From the desire to model as accurate as possible the timeline described by humans when listening to music, emerged the necessity of creating a new dataset, to provide support for recognizing emotions not only from audio features, but also from lyrics and comments features. The annotations are represented by scores in the two dimensions of emotion —valence and arousal— and lists of emotion-related word & count tuples.
Referring to the relation between the melody/audio dimension and the lyrics dimension, the question "How do people listen to music?" seems to preoccupy individuals, as it was answered on various forums and surveys:
Reading these opinions, patterns of the musical experience can be extracted and analysed. While the importance given to lyrics and solely audio may differ at first auditions, for most of the respondents listening and paying attention to the lyrics comes closely followed by trying to understand their meaning. One comment that puts these observations in a beautiful and concluding form is "enjoying the music will always be instinctual, while appreciating lyrics will always be intellectual".
The summarization of the comments on this subject can also be shaped as a timeline, as shown below:
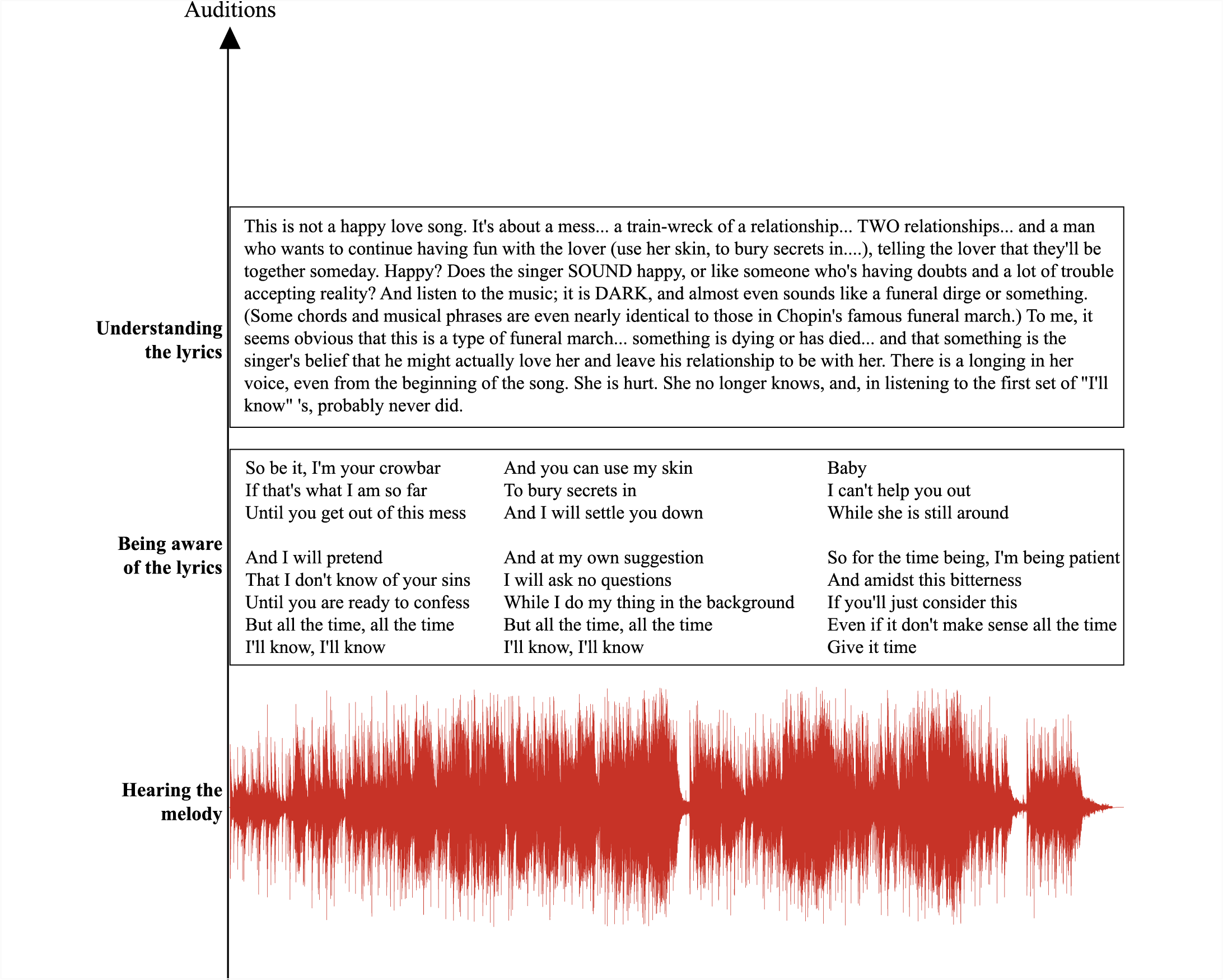
People auditioning music with lyrics - Timeline (song: Fiona Apple - I know)
Lyrics and comment source: https://songmeanings.com/.
These ideas shape the musical experience consisting in two aspects: listening —audio dimension— and understanding the meaning, that implies paying attention to the lyrics text and analysing their meaning —text dimension. This motivates the need for builing a new dataset that allows for a more comprehensive analysis and understanding of the Music Emotion Recognition task.
The Circumplex Model of Affect, defined in [Russell, 1980] , that maps emotions to a 2D space defined by valence and arousal dimensions. Valence, displayed as the horizontal axis, represents the energy of emotion, ranging from positive to negative, while arousal, the vertical axis, represents the amount of intensity in emotion, ranging from low to high. This scheme allows for a division of the emotion space in four quadrants.
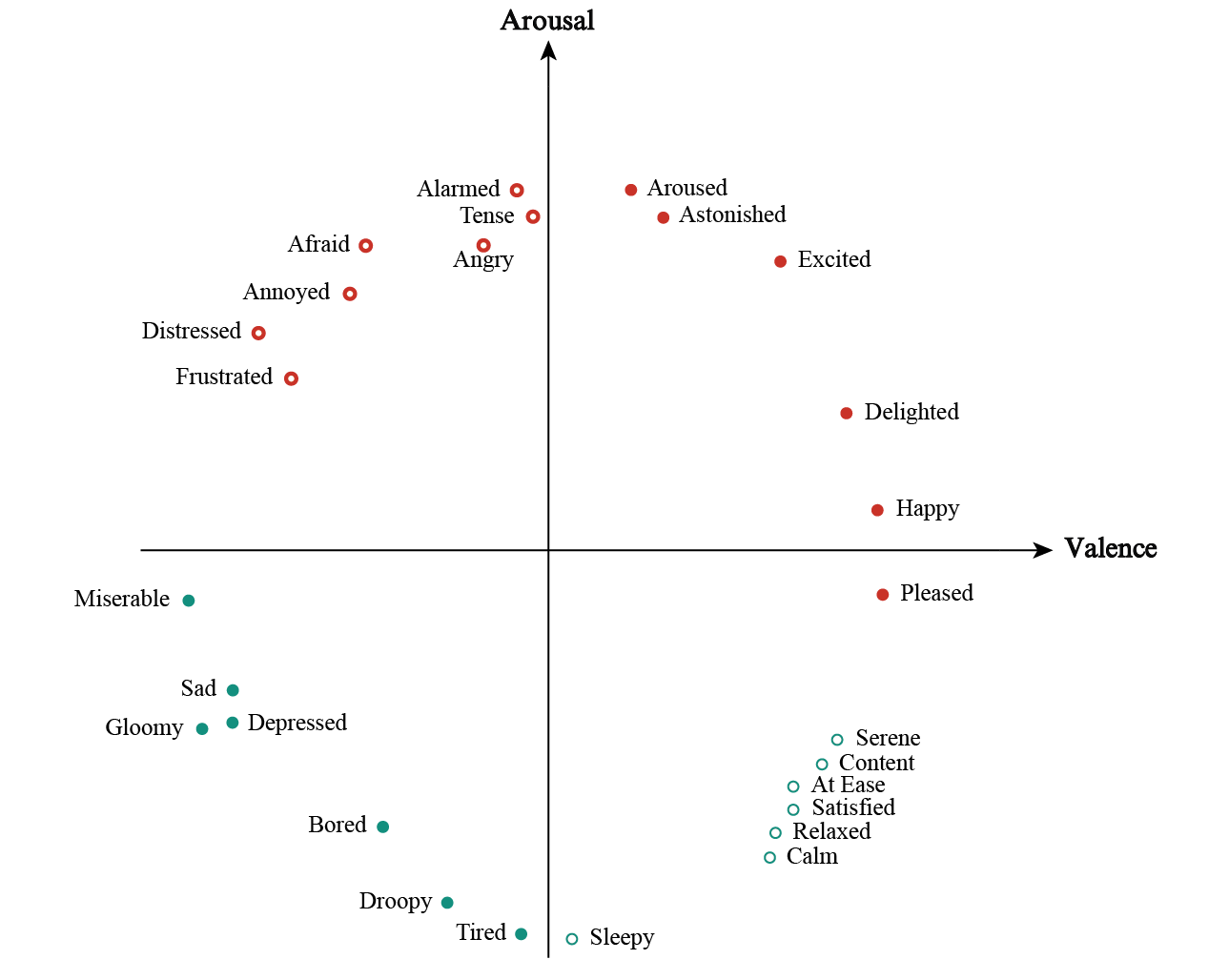
Russell’s Circumplex Model of Affect - Dimensional representation of emotions.
The largest dataset available that suits a regression approach of MER task is, at the moment of writing, the Deezer Mood Detection Dataset [Delbouys et al., 2018] . For each track, this set contains the corresponding Deezer ID, the MSD ID, the artist and title and values for valence and arousal. This data collected by researchers at Deezer is itself derived from the Million Song Dataset [Bertin-Mahieux et al., 2011] , a common support for MIR tasks in general.
For building the new dataset, the first step is selecting the songs for which lyrics and comments from users are found when scraping the web. The SongMeanings site provides both the lyrics of the songs and comments on the meaning of the lyrics, as they are interpreted by the users.
On the page of each track, the corresponding lyrics are identified by the div class_='holder lyric-box' tag and the comments section
is announced by the div class_='text' tag.
Acquiring the comments from this website comes with an important advantage that diminish
the need for additional filtering: the comments are sorted based on the number of votes
in descending order with the most voted comment -the most reliable one- listed first.
The comments are displayed on multiple pages, but the first one contains just enough
comments of good quality, therefore only the data in the first page is collected.
Starting with the 18,644 tracks selected by the researchers at Deezer, after performing
this procedure and removing the tracks that do not appear on the website or do not have
comments associated, the dataset size is reduced to 10,923 samples.
The annotation process of the new dataset is performed by following steps similar to [Hu et al.,2009] , making use of the social tags associated with songs by listeners. Mapping the tracks in the Deezer dataset to the last.fm database by their MSD ID, the social tags recorded in year 2011 can be retrieved. Along each tag associated with each song, a normalized value representing the number of listeners choosing the tag is provided.
In order to create the new dataset with information as up-to-date as possible, instead of querying the 2011 tags database, the tags available at the time of writing are acquired using Last.fm API . This allows access to a maximum of 100 tags per song, sorted by their popularity and the normalized value indicating the count of listeners attributing the respective tag to a song. Using this method, 10,919 tracks with tags are found.
The considerable volume of tags collected (795,368 unique tags) is extremely noisy and contains lot of unusable data. Therefore, to get to a format which allows mapping to emotions space, a thorough cleaning process must be performed. The musical genre, instruments names or similarity tags, along many others, are removed following the removal criteria presented, reducing the volume of social tags to 390,698:
In order to select the tags akin to an emotion descriptor, a list of affect-related words must first be composed. For this process, the affective lexicon WordNet Affect [Valitutti, 2004] is used to create the base. This list is cleaned and extended with synonyms, related words and keywords contained in expressions describing motions, found using the comprehensive Merriam-Webster online dictionary and thesaurus . These words are grouped according to their meaning in 27 emotional categories, named with a corresponding emotion, using similarity paths defined in WordNet [Bentivogli et al., 2004] and, again, the Merriam-Webster Thesaurus.

Grouping emotions extracted from tags.
Before going further, words related to emotions, but which, in the context of social tags, could have ambiguous or judgmental meaning are removed from the list, as suggested in [Hu et al.,2009] . Therefore, appreciation remarks such as 'awesome', 'bad', 'fantastic', 'good', 'great', 'horrible' which refer to the quality of music and preference words like 'adore', 'like', 'love', 'hate' which might lead to ambiguous interpretations, are removed from the list of emotion-related words.
In order to include all possible forms of the emotion-related words, they are stemmed to a root using the Porter Stemmer functionality provided in the Natural Language Toolkit . By searching tags containing these stems, they are also grouped, according to the stems' membership in the emotions clusters, discarding the tags not containing any of the stems of the emotion-related words. Following, a manual selection of tags is performed, as not all tags containing stems of affective words describe an emotion perceived when listening to a particular song. Tags that could, at the same time, be mapped to a positive emotion and to a negative emotion are identified and removed. Some of these tags with ambiguous meaning found are 'to listen when sad', 'to listen when happy', 'music for sad days', music for when you feel down'.
After this curation phase, each song has its remained tags replaced by the emotion words describing the clusters the tags are part of. It is important to mention that the normalized values associated with each tag at song-level, are taking into account when mapping the tags to valence and arousal values. At this stage, after removing the songs without at least one tag with affective information, the dataset size is reduced to 10,579 samples. Therefore, for each song, the tags are transformed into the words describing the emotions clusters, keeping their corresponding normalized count. In the case when more tags are mapped to the same word, the normalized count of the representative word is obtained by summing the values of the tags.

The process of converting social tags to emotion-related words.
Tags acquired from Last.fm(https://www.last.fm/home) - Song: Fiona Apple, I know.
The NRC VAD Lexicon comprises more than 20,000 English words with associated ratings of valence, arousal and dominance given by human annotators. The annotators were presented with groups of 4 words from which, besides assigning real values of emotion dimensions, they had to choose two words following a Best-Worst Scaling technique. The final scores for each word were obtained by using the real values along with the proportions the respective word was ranked as best or worst and scaling them to range 0 .. 1.
Using this resource, the 27 words representing emotions are embedded into valence-arousal space, taking into account their summed count at song-level. For every song, the valence and arousal scores extracted from the VAD Lexicon for each word are multiplied by the normalized count and the final ratings for the song are obtained by computing the average of the sum of the weighted values for valence and arousal dimensions:
where S is a song in the dataset and w an emotion word in S.
This annotation strategy resulted in an unbalanced distribution of the data in the 2D space of emotions, with quadrant 2 appearing heavily underrepresented. This reveals that strong negative emotions such as 'anger', 'aggressivity' are not frequently perceived in music.

Distribution of data from the new dataset in the four quadrants of the 2D space of emotions.
The next phase in creating a new dataset with valid information, is updating the Deezer IDs for the 10,579 annotated tracks. A number of 607 tracks are not found on Deezer platform and for 1,441 tracks with outdated IDs, replacements are found, with identical artist name and song title.
Another filtering process is performed considering the duration of songs and 32 more tracks are removed, bringing the dataset to a size of 9,972 samples.
The raw lyrics data contain a great amount of noise, as they are written by different users on https://songmeanings.com/, with no set of rules or format to be followed. Therefore, cleaning the lyrics data is a meticulous process that involves manual curating and a considerable amount of time. The lyrics have a particular structure, different than usual text data. Hence, before applying cleaning procedures commonly used in NLP tasks, this structure is studied for patterns identification with the scope of finding a set of rule that allow for automatization.
In the raw lyrics text, there are different types of tags, such as repetitive instructions ('repeat', 'x2', 'repeat once', etc.), announcement of artists singing a particular part of the song ('[eminem]', '[all:]', '2pac', etc.), structural information ('chorus', 'verse', 'bridge', 'pre-chorus', etc.). As a result of a series of manual transformations and removals, different types of patterns are revealed and used for automatization of the cleaning process. In differentiating between the types of patterns discovered, the newline (\n) character has the greatest role. The most important patterns are ones playing a role in changing the text of lyrics, as described below:

Identified and created patterns leading to modifications in lyrics text \n - newline character, N - number of repetitions.
The structural instructions are another class of patterns discovered, with no relevance for the strategy chosen in recognizing emotions in music, therefore are removed from the lyrics text. They may contain tags present in the important patterns mentioned earlier, but in different configurations, as defined by the occurrence of the newline character.

Structural patterns in lyrics text.
These transformations bring the lyrics text to a format that allows applying common preprocessing techniques used in NLP tasks.
Starting with the texts in string format, the following transformations are applied:
The steps presented above conclude with tokenization, converting the texts into lists of words. The preprocessing phase ends after curating the words resulted, as follows: