This project presents the implementation of CT super-resolution using multiple dense residual block based GAN presented in [Zhang et al., 2020], with slight changes as recommended in [Gulrajani et al., 2017] and with architecture parameters adapted from [Ledig et al., 2017], in case they were not specified.
The authors propose a generator structure with dense connections between residual blocks in order to reduce the network redundancy. In the computation of the loss function, they introduced the Wasserstein distance and a perceptual loss value extracted from feature maps obtained by a VGG-19 feature extractor.
The Generator recieves a low-resolution CT image as input and learns towards generating super-resolution CT image to match the high-resolution CT image. As displayed in the image below, based on the author best results, the Generator architecture is represented a collection of 4 densely connected Residual Blocks, each of them consisting in 4 linked Residual Units, followed by Convolution and Batch normalization layers. Through skip connections, the low-resolution CT image is added to the output obtained from the first part of the generator and fed to another Convolution layer, followed by a flattening operation (for which I choose convolution with 1 kernel) and non-linearity induced by Parametric ReLU.
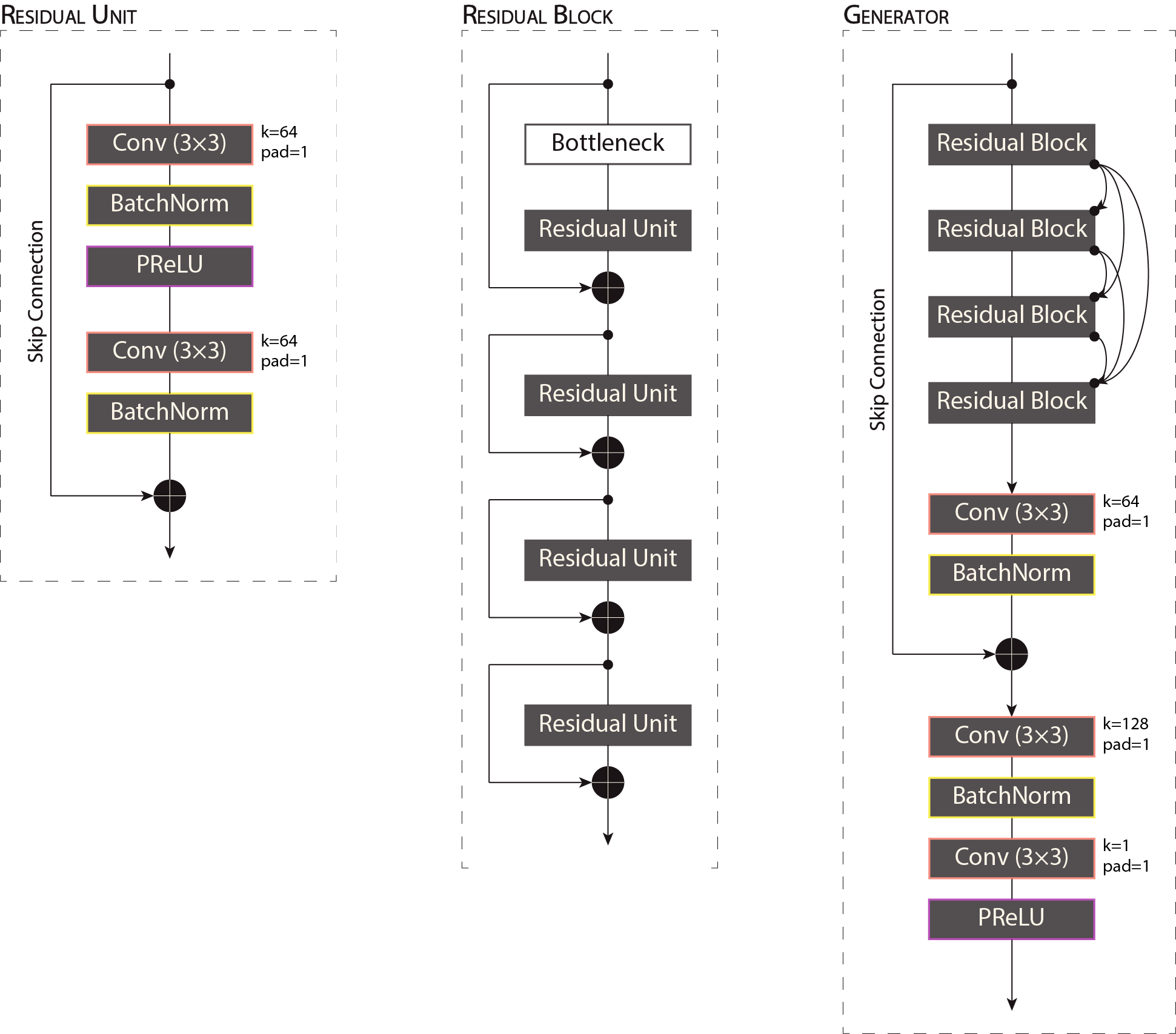
Architecture of the Generator model.
Since some of the design parameters were not provided, I adapted this structure using kernels size as proposed in [Ledig et al., 2017].
The super-resolution CT images generated and the high-resolution CT real images are fed to a feature extractor, represented by a substructure of the VGG-19 model [Simonyan & Zisserman, 2015].
Based mainly on the structure presented by the authors and with adaptations inspired again by [Ledig et al., 2017], the Discriminator architecture is composed of 8 Convolutional blocks with the same structure, excepting the first one. The number of convolution kernels is increased by a factor of 2, with alternating strided and not-strided operations, following the VGG network scheme. This part outputs 512 feature maps (representations of the super-resolution CT image or the high-resolution CT image), which are fed to a sequence of 2 linear layers with Leaky ReLU activation. The output of the discriminator represents the probability the input CT image is the high-resolution CT image.
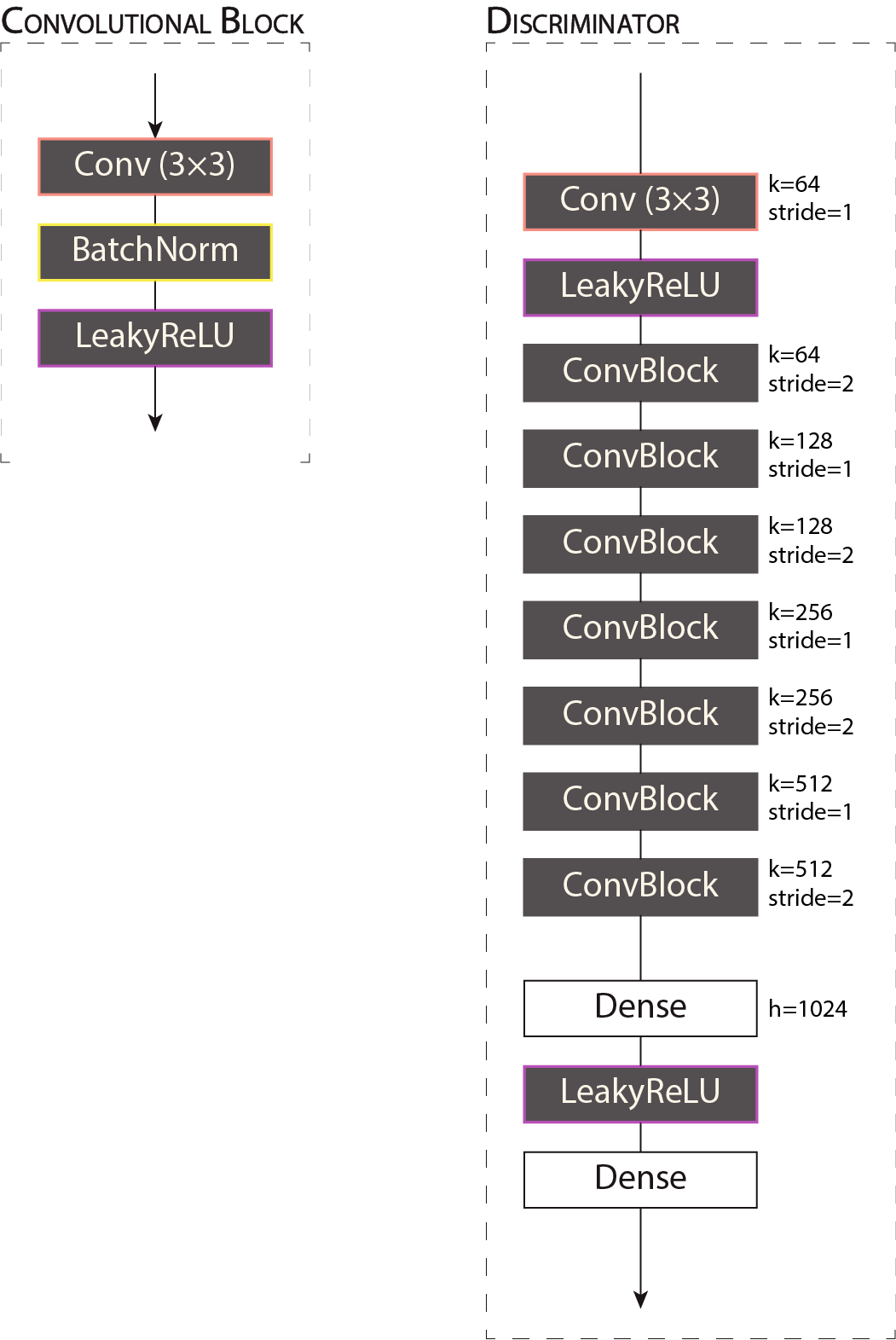
Architecture of the Discriminator model.
The complete architecture of the Generative Adversarial Network based on multiple dense residual blocks is displayed below:
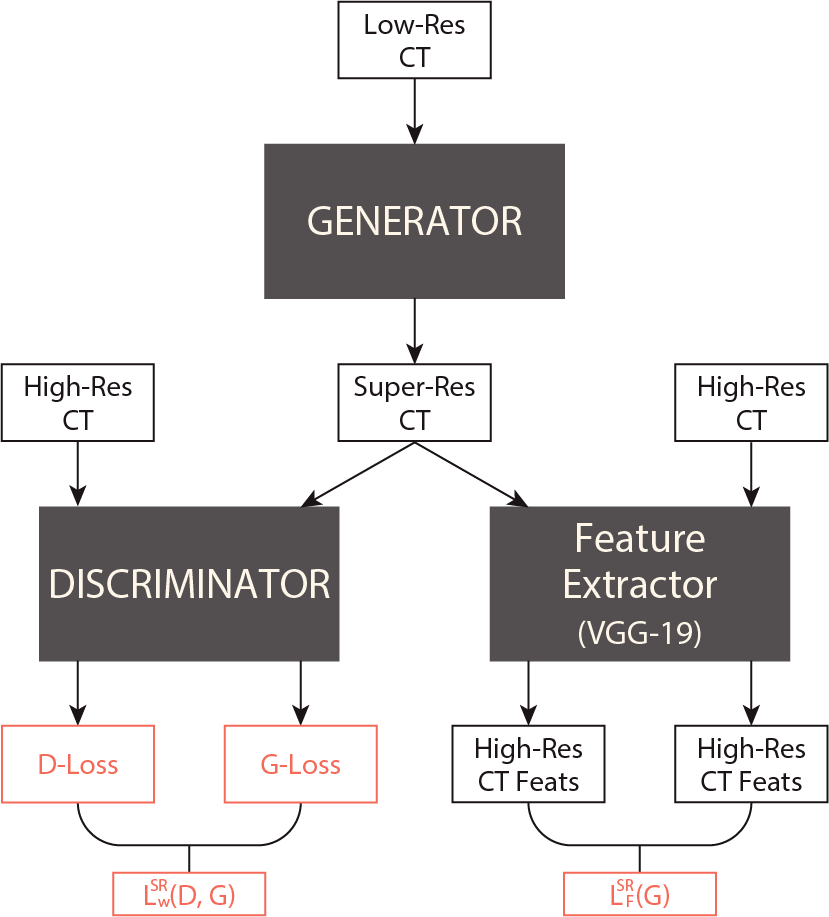
Overall architecture of the proposed model.
The Generator receives low-resolution CT images as input and generates super-resolution images.
The generated image, along with the real high-resolution CT image are fed to the VGG-19 Feature Extractor, resulting in feature maps, used to compute the F-loss involved in the optimization of the generator parameters.

F-loss formula.
The discriminator is designed for use with Wasserstein-loss with gradient penalty, as described in [Gulrajani et al., 2017]. Receiving as input low-resolution or high-resolution CT images, it outputs the probability score of the input being discriminated as high-resolution image.
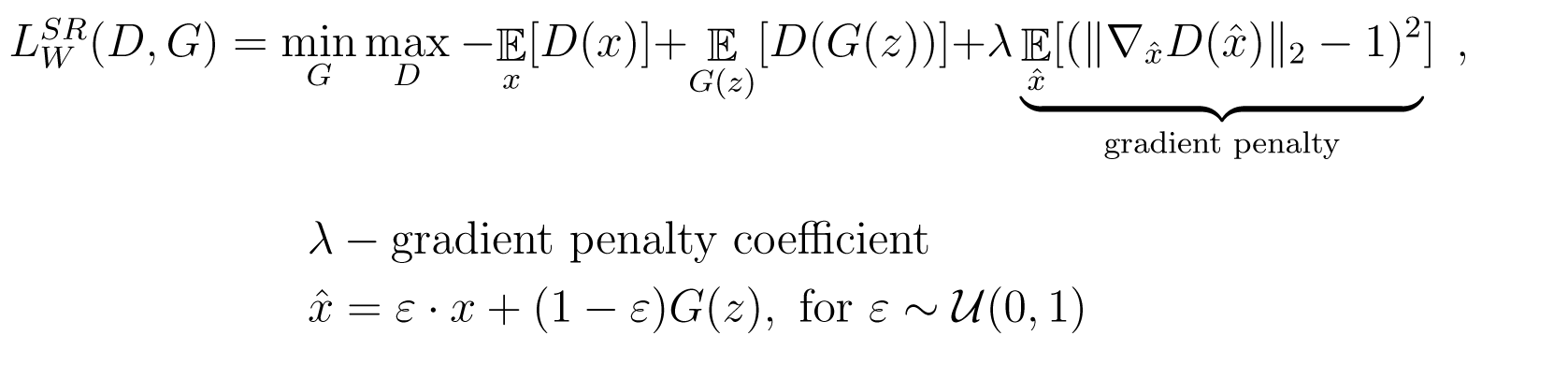
Wasserstein-loss formula.
Based on the formulations described above, the overall objective function, can be defined as follows:
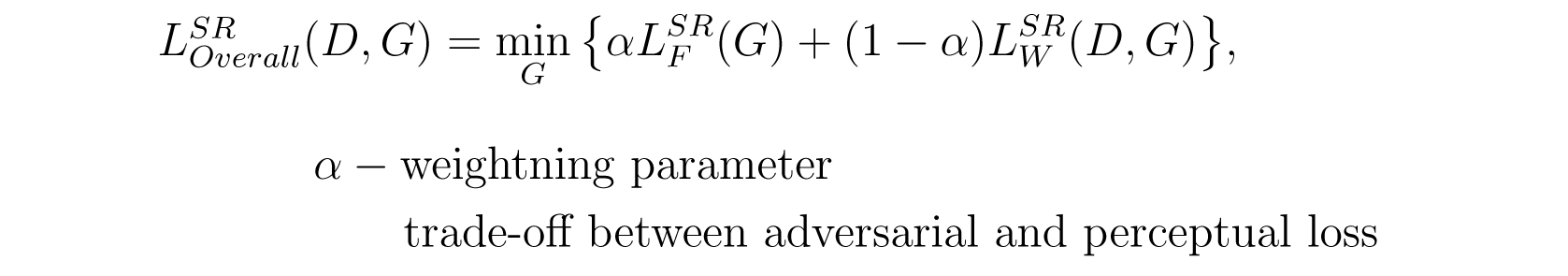
Overall Objective function.
The generator and discriminator loss functions are modified in the following manner:
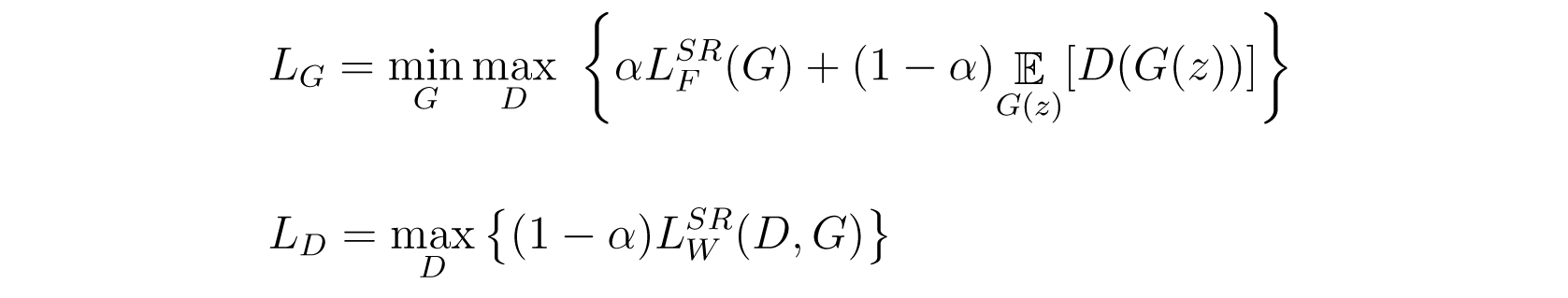
Generator loss function (top) and the discriminator loss function (bottom).
The training is carried out on 96×96 non-overlapping patches extracted from 512×512 CT images, in batches of 16. The pixels values are truncated and the images are scaled to interval 0 .. 1. The low-resolution CT images are obtained by scaling down the high-resolution CT images by a factor of 4, followed by upscaling to the original dimension using bicubic interpolation.
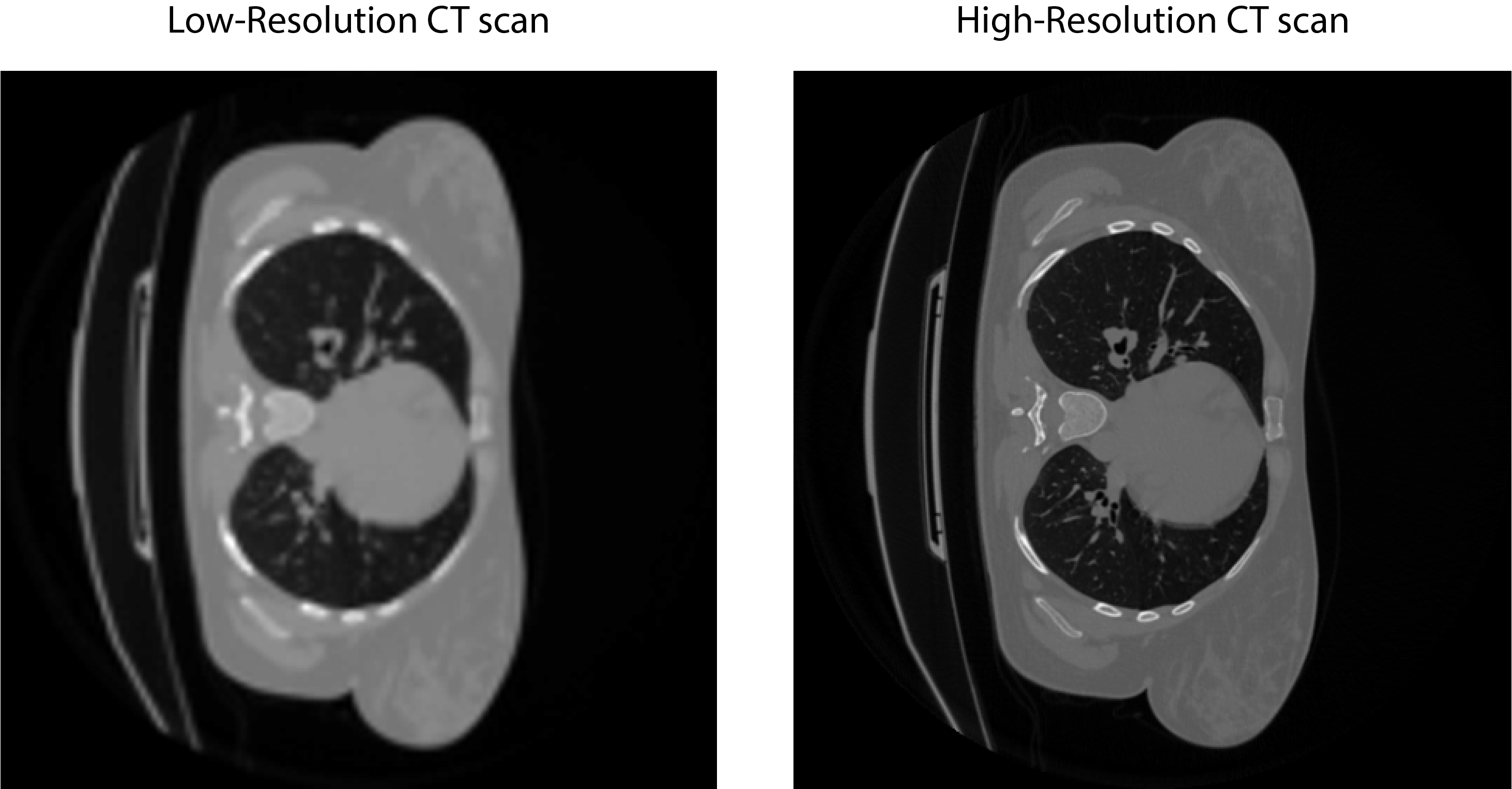
Training CT data: low-resolution image (left) and high-resolution image (right).
Different than the solution proposed by the authors, the optimization of the discriminator and the generator are performed by Adam optimizer with initial learning rate of 1e-4 and decay factor of 1e-1. Following the recomendation in [Gulrajani et al., 2017], the discriminator parameters are updated 5 iterations for each update of the generator parameters.
For the evaluation phase, the learned weights are applied to patches of size 128×128 obtained by dividing unseen CT slices, in order to be able to reconstruct the image, as illustrated below. The low-resolution CT images are obtained the same way as in the case of the train data.
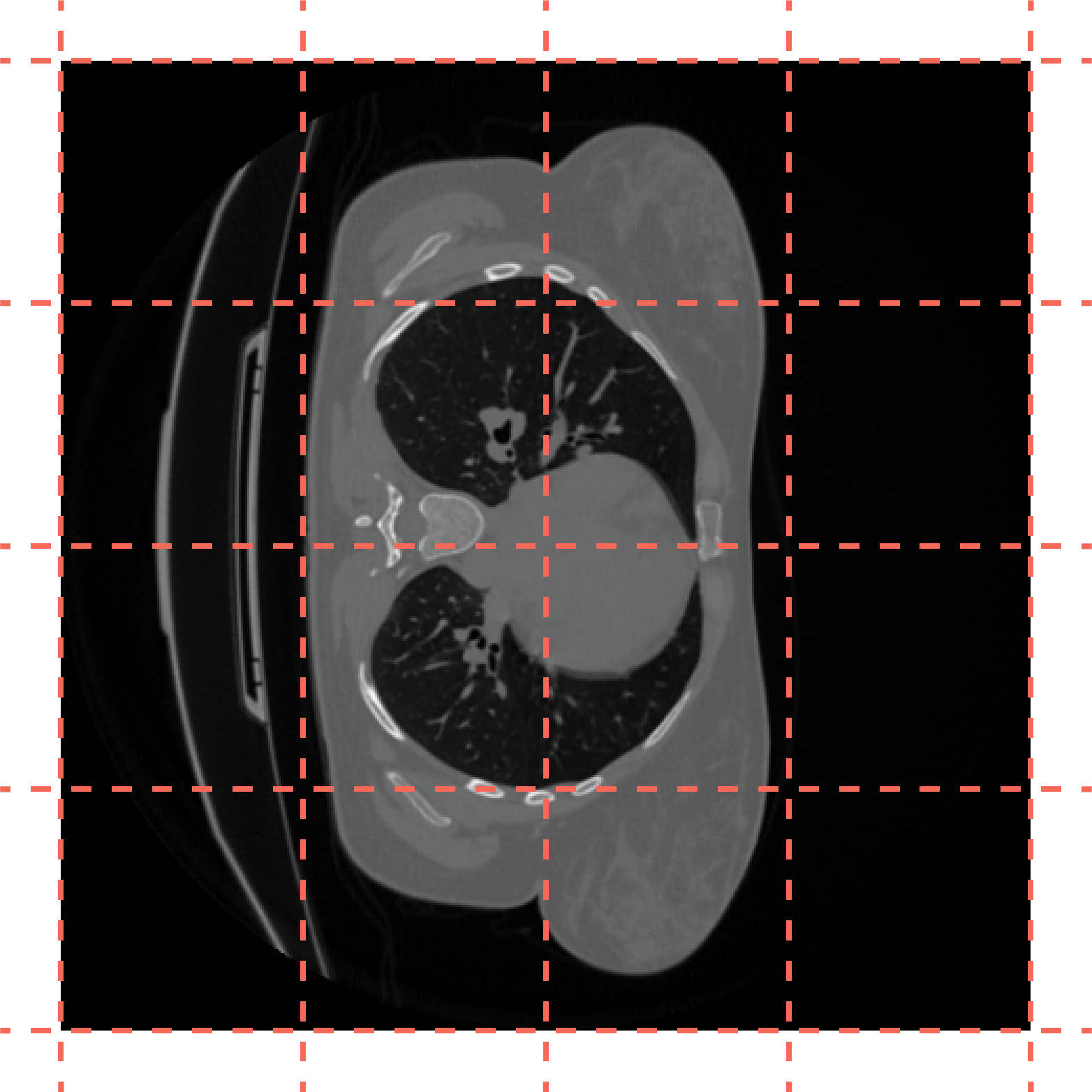
Dividng the test CT slices in 128×128 patches.
The experiment was carried out on a small subset of the MosMed COVID-19 Dataset [Morozov et al., 2020]. The dataset consist in multiple chest CT scans of healthy and infected patients, with different number of scan slices and slices thickness.
Restricted by the high computational resources needed to conduct an experiment as described by the authors, I selected 16 CT scans for training, 2 CT scans for validation and 6 CT scans for testing and used only 1 slice from each scan.
Using the parameters described above, the model was trained and tested on the validation data for 1500 epochs. I find the evolution of the generated images interesting to observe and gain insights on the convolution operations and patterns discovered during training.

The experiment concludes with testing the trained GAN model on the unseen CT slices, with the results shown below:
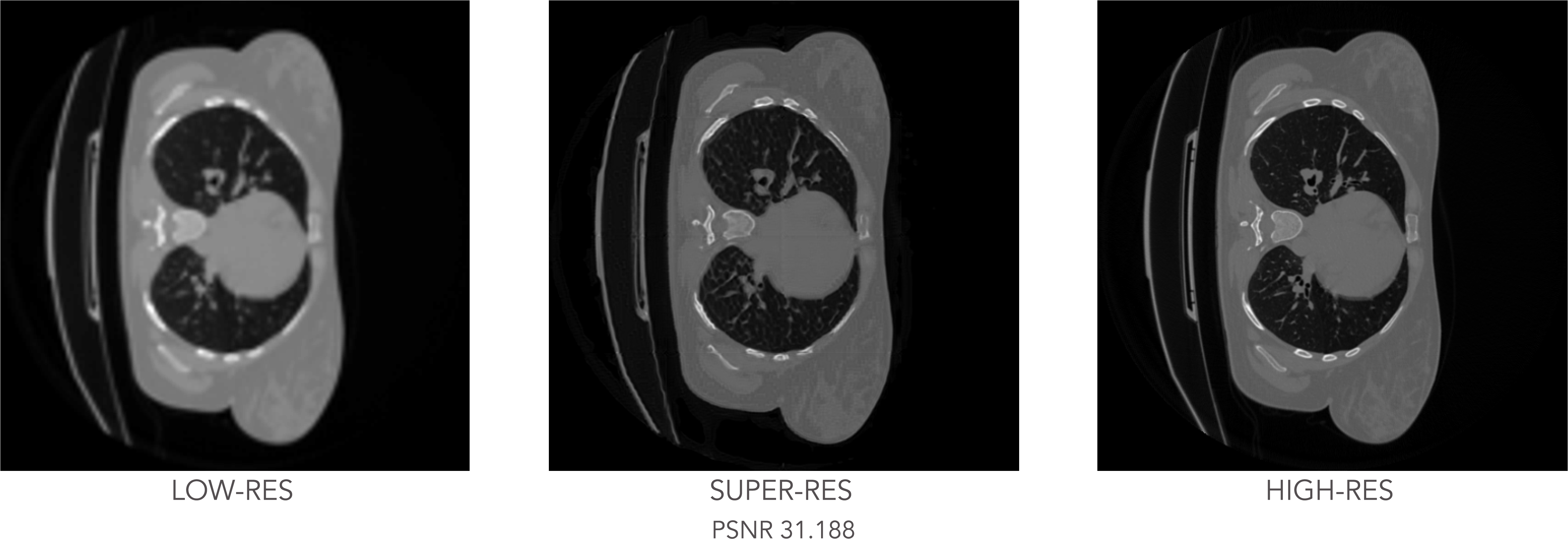
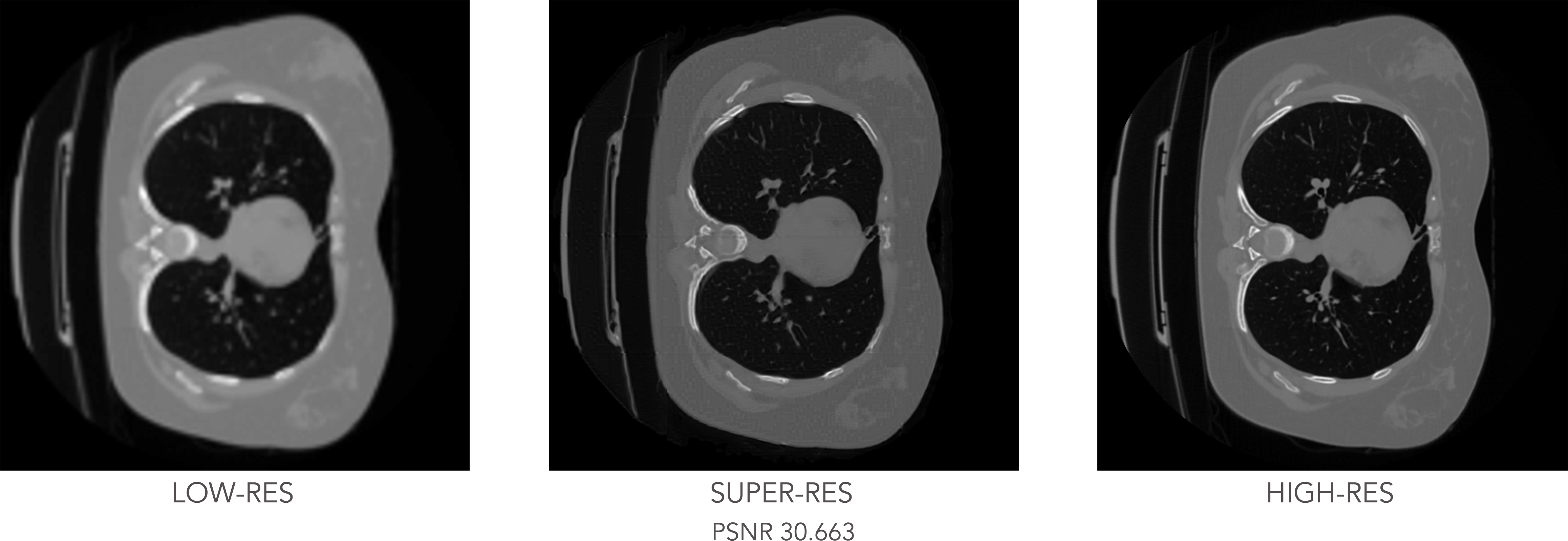
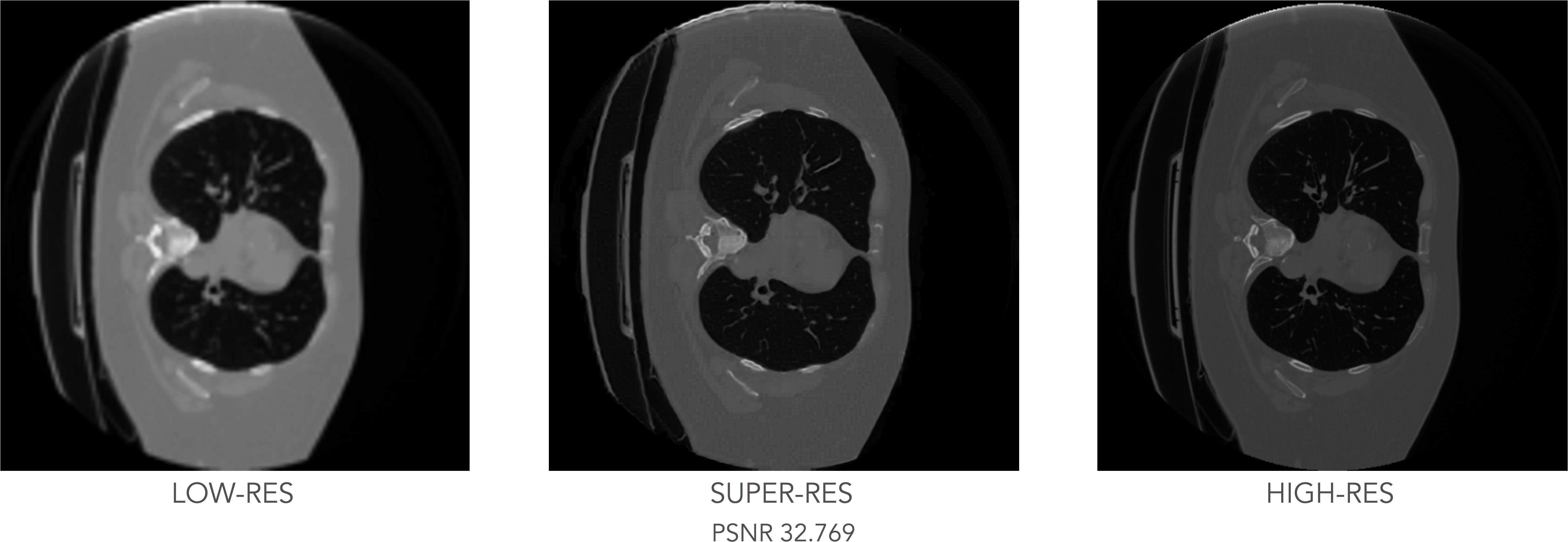
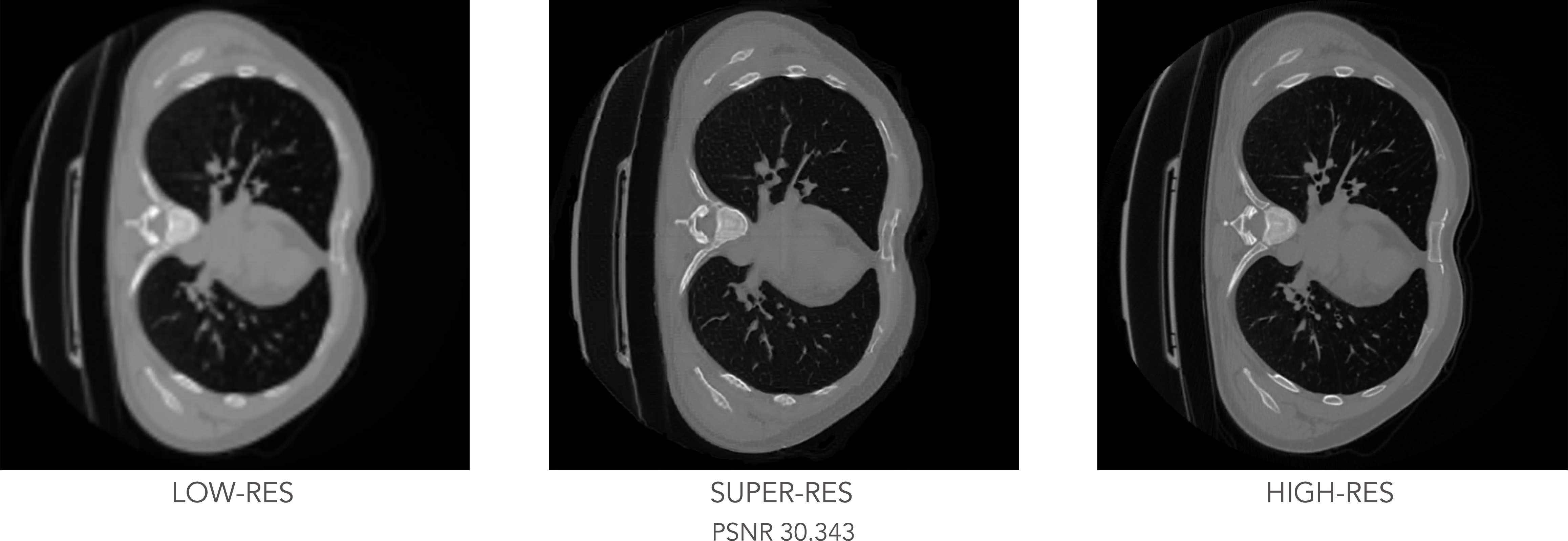
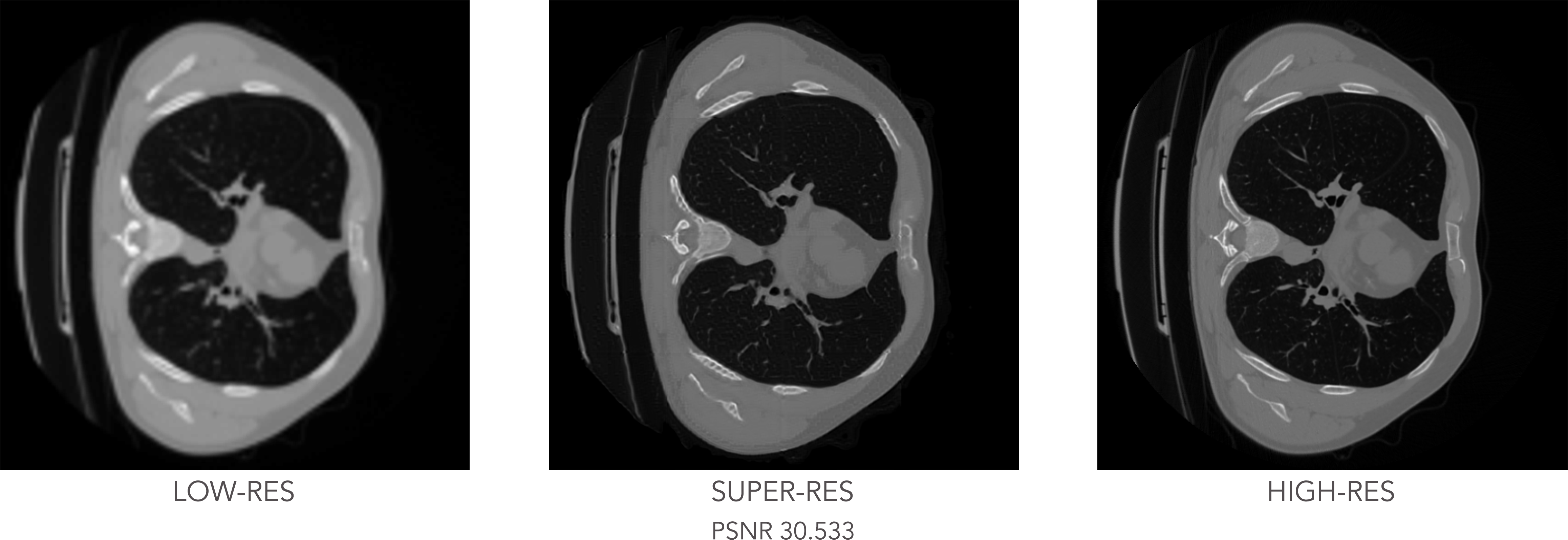
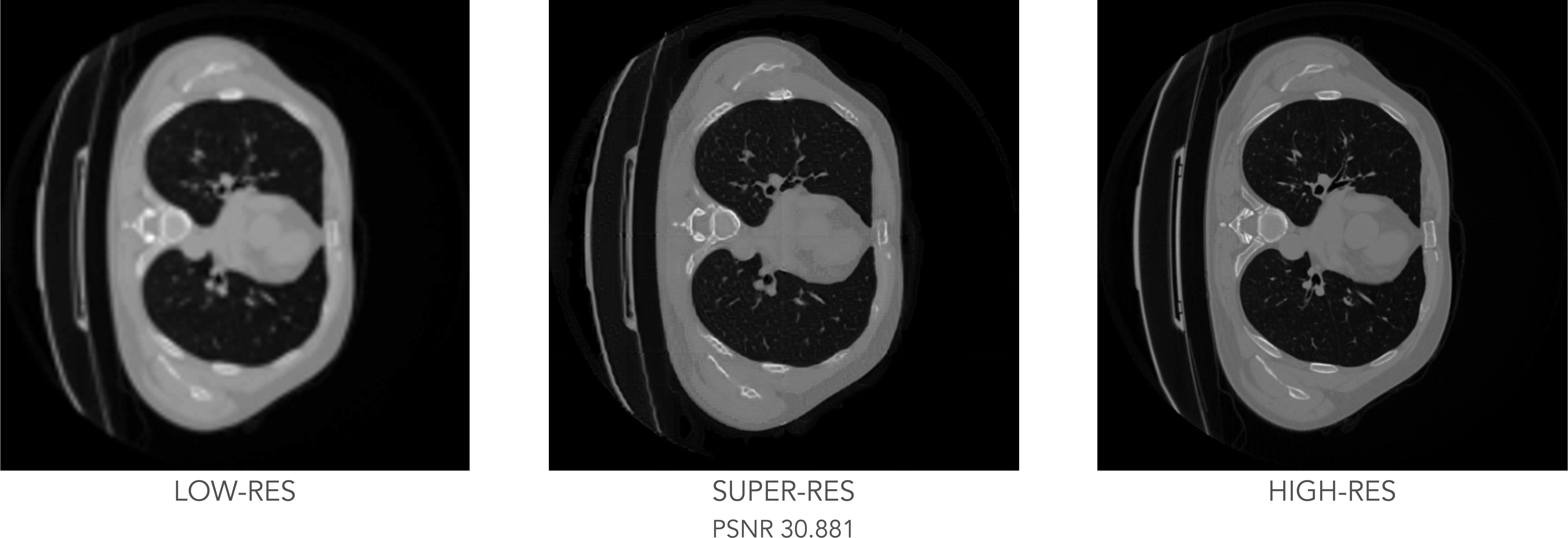
Test results: low-resolution input image (left), generated super-resolution image (center) and real high-resolution image (right).