Inspired by the timeline described by people in the context of a musical experience and based on the New multimodal Dataset created, this project describes different approaches to MER. Starting with individually treating the musical dimensions, emotions are predicted solely from audio, lyrics or comments features. Following, using combinations of this modalities, specifically audio - lyrics and audio - comments, fusions of models are designed to recognize emotions.
The experiments lead to a discussion on the role including different musical dimensions has on learning to recognize emotions from music, by analysing jointly the unimodal and multimodal approach results.
This concludes with an investigation of the tools and methods used, from the quality of the annotations, to the features chosen to represent the text modalities.
As noted in [Unimodal MER], the imbalance in the dataset affects negatively the performace of neural networks. This leads to the need of augmenting the new dataset. As observed in [New Dataset], the second quadrant is considerably underrepresented. To correct this unequal distribution of data in the space of emotions, the first step in this direction consists in duplicating samples in the underrepresented quadrants and removing samples chosen randomly in the overrepresented ones, until the fixed size of 3000 samples in each quadrant is reached. Then, the data representing each modality is treated accordingly to their particularities.
The audio samples are reduced to an excerpt, by sampling the the beginning of the cropped segment from an uniform distribution, with the scope of gathering audio properties from different parts in song. The length of the excerpts is set to 73sec, aiming to capture as much of the initial signal as possible. This length is further reduced to 45sec, by keeping the first 3sec from consecutive non-overlapping 5sec segments. Although not ideal, this approach is motivated by the desire to obtain comprehensive information from a song, considering the limited computational resources.
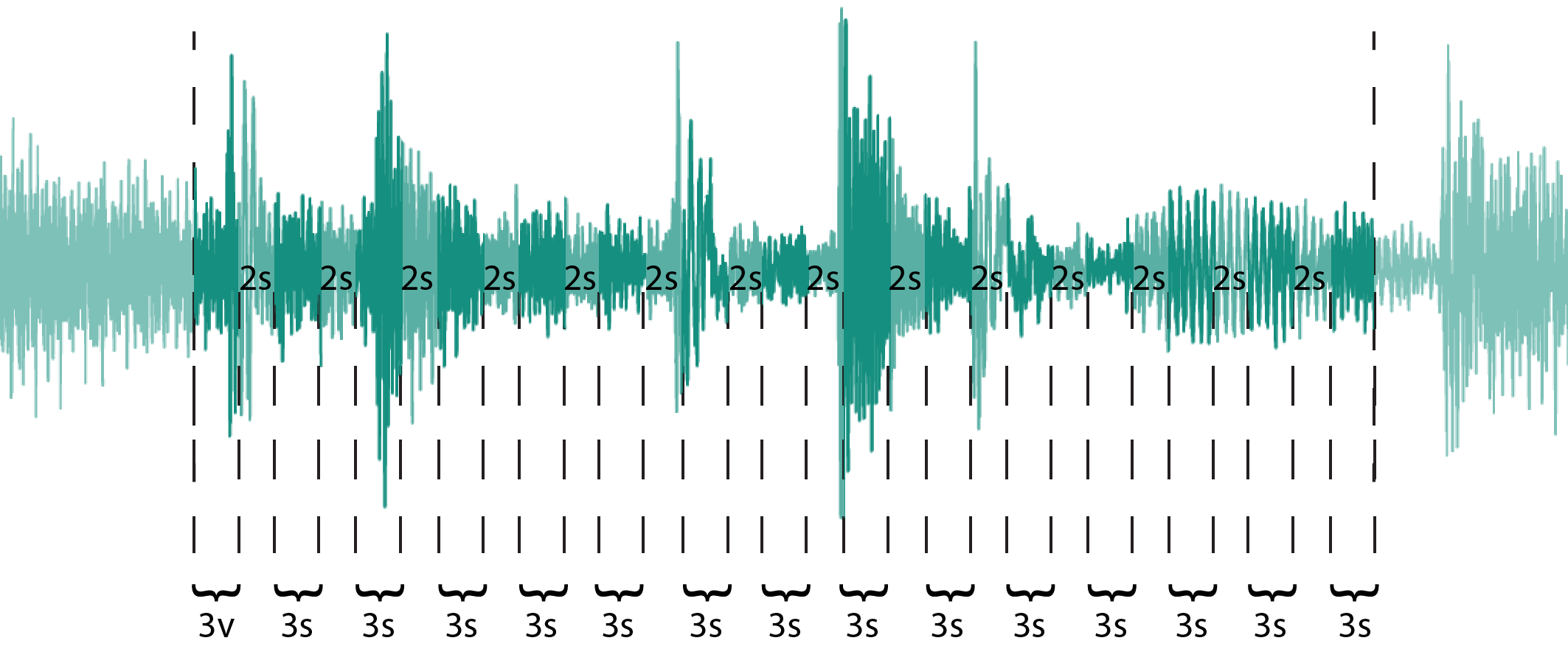
Audio data augmentation technique.
Having similar format, the augmentation of lyrics and comments data is presented jointly. The method chosen to obtain augmented representations for the same sample, is by replacing 20% of the words, in case of duplicates, with their synonyms, using synsets provided in WordNet.
To represent the audio signal, the MFCCs features are extracted from the audio sample divided in windows of 30ms duration. Therefore, from each 45sec audio excerpt sampled at 22,050Hz/sec, are obtained MFCCs features with the size 20×1502. Before feeding the features set to the neural network, these are normalized using the Cepstral Mean and Variance normalization technique, resulting in data centered with zero mean and unit variance.
One more pre-processing step needs to be done before extracting features from lyrics and comments, specifically stemming the words to their root, achieved by using the same Porter stemming algorithm.
The representations chosen for the text features are Word2Vec embeddings [Mikolov et al., 2013] After several trials, the number of features chosen to represent the words in the context space is set to 300 and the sequence length of each sample is fixed to 500 words.
The experiments presented further are designed considering the music emotion recognition task as a regression problem, therefore, the predictions are real values for the valence and arousal dimensions of the emotions space.
The conclusions drawn from the DEAM experiments represent the foundation the next approaches are based on, but they are conditioned by the computational power available. Hence, also influenced by the large dataset size, instead of building groups of two models, each predicting values in only one emotional dimension, there will be used models with 2D-outputs. Observing the CNNs behaviour and performance, the configurations created for the following experiments are based on architectures with convolution layers.
Given the generous size of the new dataset, the data is split in three sets: train, validation, test. The training, testing and validation are performed on batches of data of size 64. This size is suitable for both generalization and prevention of noisy gradients.
Every training process is optimized using SGD and the cost at every training moment is based on MSE criterion. The regularization strategy consist in applying the L2 penalty when updating the parameters and by introducing Dropout layers.
The first experiments are conducted based on one modality at a time, using the features previously extracted, with the finality in further creating fusions between modalities and conduct a comparative analysis on these methods.
The first model created is trained on the audio features with size 20×1502, representing the MFCCs extracted from 45sec audio excerpt sampled at the rate 22,050Hz. The first dimension is given by the number of Mel-coefficients used and the second dimension represents the number of windowed segments obtained from the initial signal. The convolution operations in the model are based on one-dimensional kernels. Therefore, the 2D image-like format of the features is converted to 1D format with 20 channels.
For this approach, I considered a convolutional block with a 1D-Convolution layer with kernels of size 10 and stride 1, followed by Batch normalization, ReLU activation and subsampling by applying an Max Pooling layer with kernels of size 4 and stride 4. The architecture of the odel consist in two convolutional blocks, followed by an Average Pooling layer with kernel of size 4 and stride 4, thus reducing the size of the feature maps, as method of preventing the overfitting to occur. The flattened output of this layer is forwarded to a linear layer with 64 hidden units. This is followed by ReLU activation and finally, performing one more linear operation, the data is mapped to the 2D-output. Dropout layers are introduced before each linear layer, with a probability of 50%.
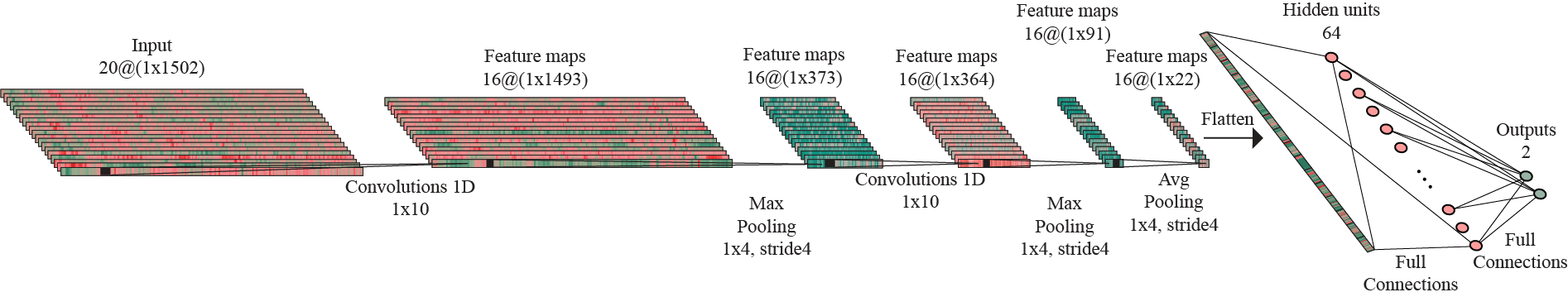
Architecture of the model trained on audio features.
Analysing the model's performance metrics, the difference in the value of the coefficient of determination is clearly visible, suggesting a much stronger relation between the audio modality and the arousal dimension. This is not necessarily surprising, as the intensity of an emotion is much easier evoked by the pitch of the audio, when compared to the energy of the emotion.
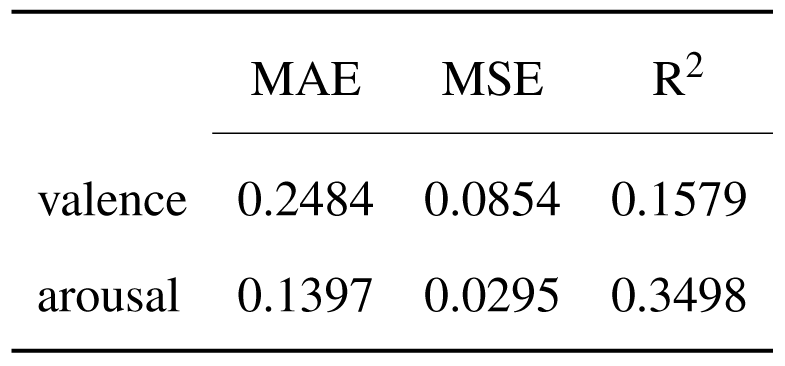
Performance metrics for the model trained on audio features.
These unsatisfactory results may have the cause in the annotations process, where scores for valence and arousal were extracted from social tags and were associated to the entire songs, not only the audio excerpts used as input data. This observation raises the question of reliability of the annotations.
For a better understanding of the model's behaviour, the numeric scores are paired with visualizations of the predicted values compared to the observed values. The differences in the R2 scores for the two dimensions is also reflected in these visualizations, where the predictions for valence only slightly fit the observed values, while in the case of arousal, the predictions appear much closer to the expected values.
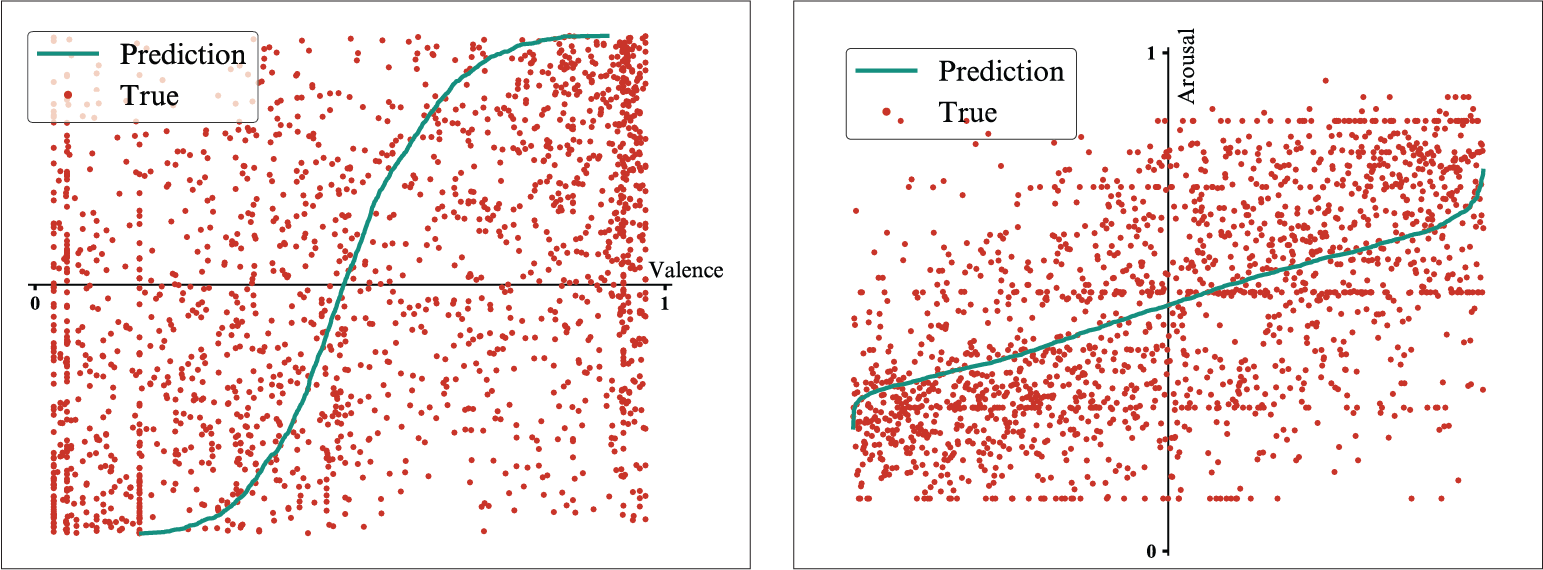
Model trained on audio features - Results for the valence dimension (left) and the arousal dimension (right).
The values predicted cover a narrower range than the observed values, with bigger differences in the arousal dimension. This aspect reflects in the gathered display of the predicted values in the four quadrants.
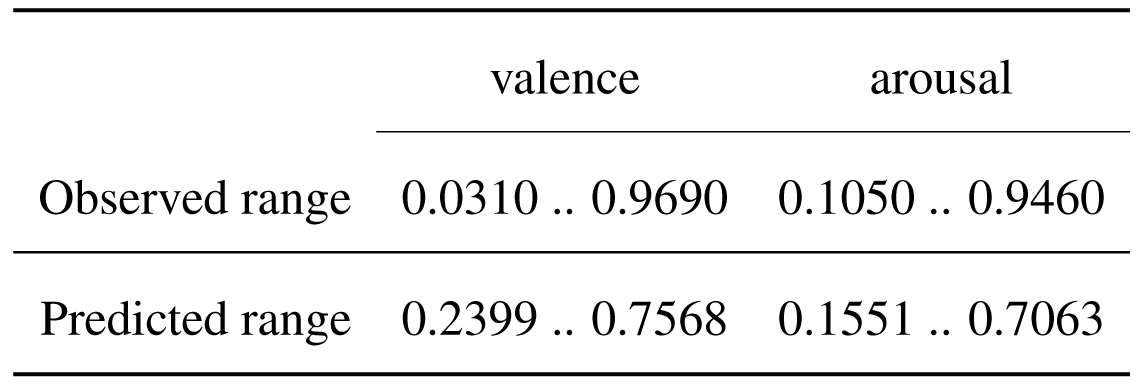
Ranges of observed and predicted values for the model trained on audio features.
Another observation regarding the distribution in the emotion space is the rather balanced accuracy of the predictions judging by the classification in the four quadrants, indicating the augmentation process was properly performed.
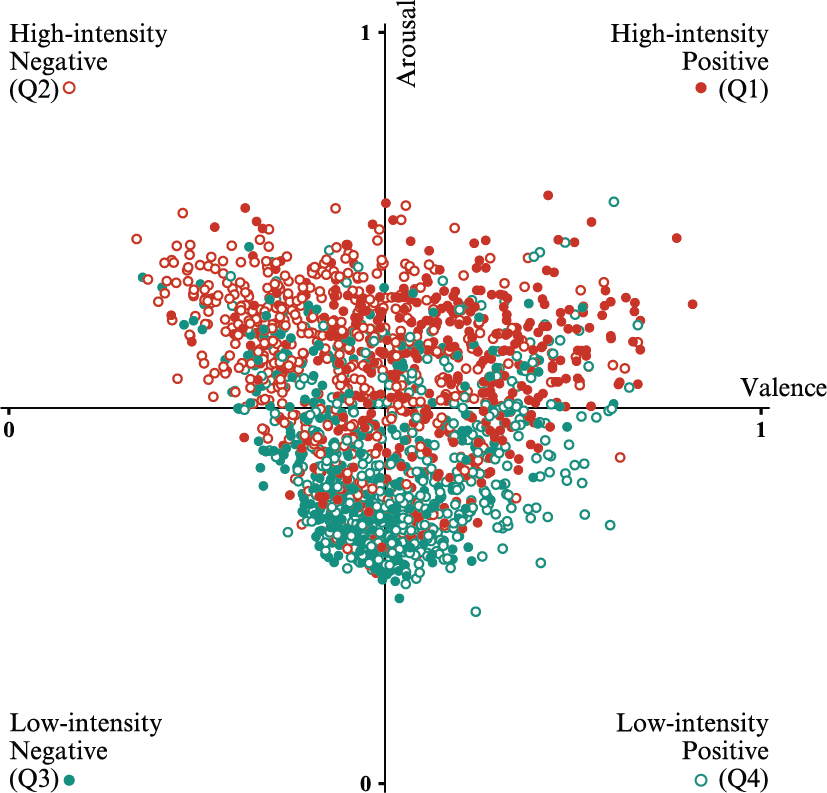
Model trained on audio features - Results for valence and arousal in the space of emotions described by the four quadrants.
The next experiments consist in training two models on the lyrics features and on the comments features, respectively, both with size 500×300, representing the vector embeddings of the lyrical or comments text. The first dimension denotes the length of the sequence and the second dimension is given by the number of features in the word2vec embedding used to describe each word.
In order to apply convolution operations with 2D kernels on these sets of features, an additional dimension must be artificially created, representing the number of channels (one channel in this case).
Each of these modalities is approached using a CNN architecture on the pre-trained embedded representations of lyrics and comments data, composed of one 2D convolution layer with kernels of size 10×300 and stride 1, that cover the entire feature dimension at a time, followed by a Batch normalization layer, with non-linearity induced by ReLU activation and subsampling by applying a Max Pooling layer with kernels of size 2 and stride 2. Added to this is an Average Pooling layer with kernel of size 4 and stride 4, that reduces the size of the feature maps and has a role in preventing the overfitting to occur. The flattened output of this layer is forwarded to a linear layer with 32 hidden units. By performing one more linear operation, the data is mapped to the 2D-output. Each of the last two linear layers are preceded by Dropout layers with a probability of 50%.
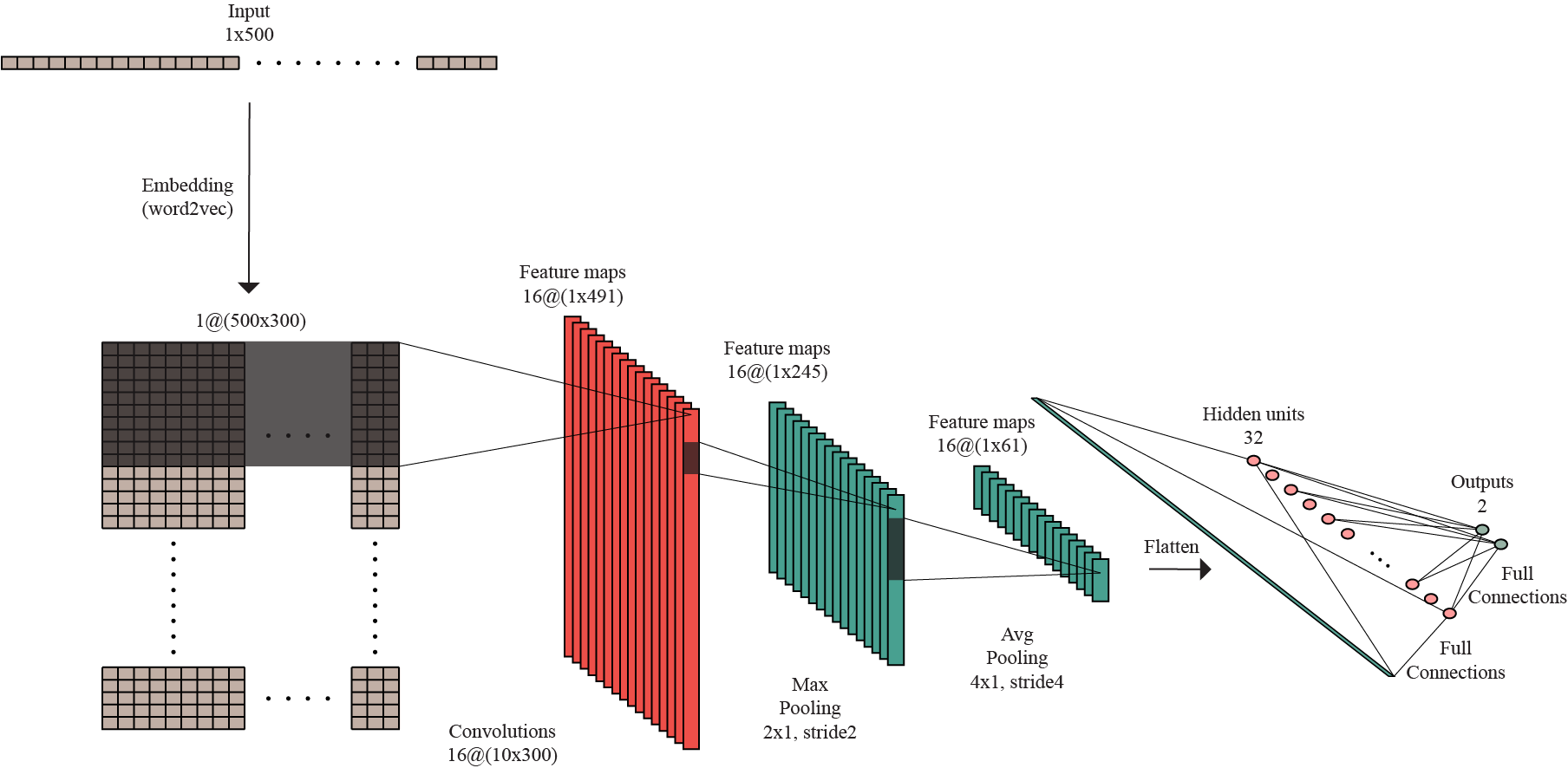
Architecture used for the models trained on lyrics features and on comments features.
The training process is performed separately in the case of each modality: one model is trained on the lyrics embedded representations and another model is trained on the comments embedding, both having the same architecture described above. The performance of these two models is discussed jointly, with their results displayed side-by-side.
For a legible differentiation between the two models, the following name conventions are defined: when referring to the model trained on lyrics features, lyrics model and lyrics CNN are used interchangeably, while comments model and comments CNN announce the model trained on comments features.
Evaluating their performance using the metrics displayed below, it is observable that both text features have a greater influence on the valence dimension than on the arousal dimension and the relation between the comments features and valence is stronger than the one between lyrics features and valence predictions. This observation is according to the human perception of emotions, as it is easier to extract one or multiple emotions from the explained meaning of the lyrics, than it is from the original lyrics. It also shows in the error values, the model trained on embedded representations of comments making better predictions in both valence and arousal dimensions.
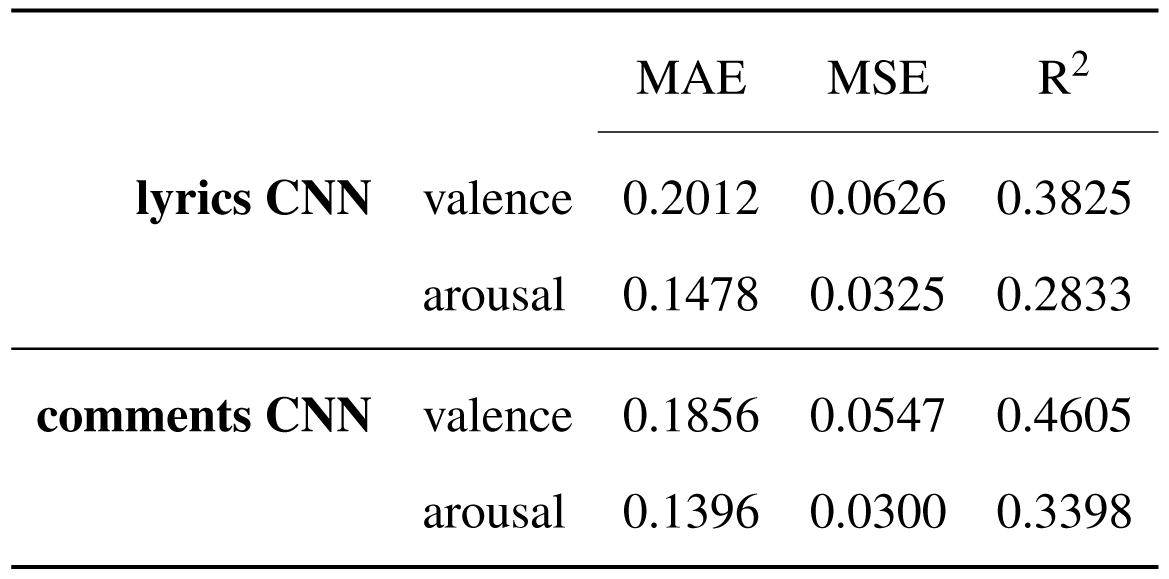
Performance metrics for the models trained on lyrics features and on comments features.
These measurements are paired with visualizations of the predicted values compared to the observed values for the lyrics modality and the comments modality, where the smaller errors in the predictions made by the comments model are highlighted again, especially in the case of the valence dimension.
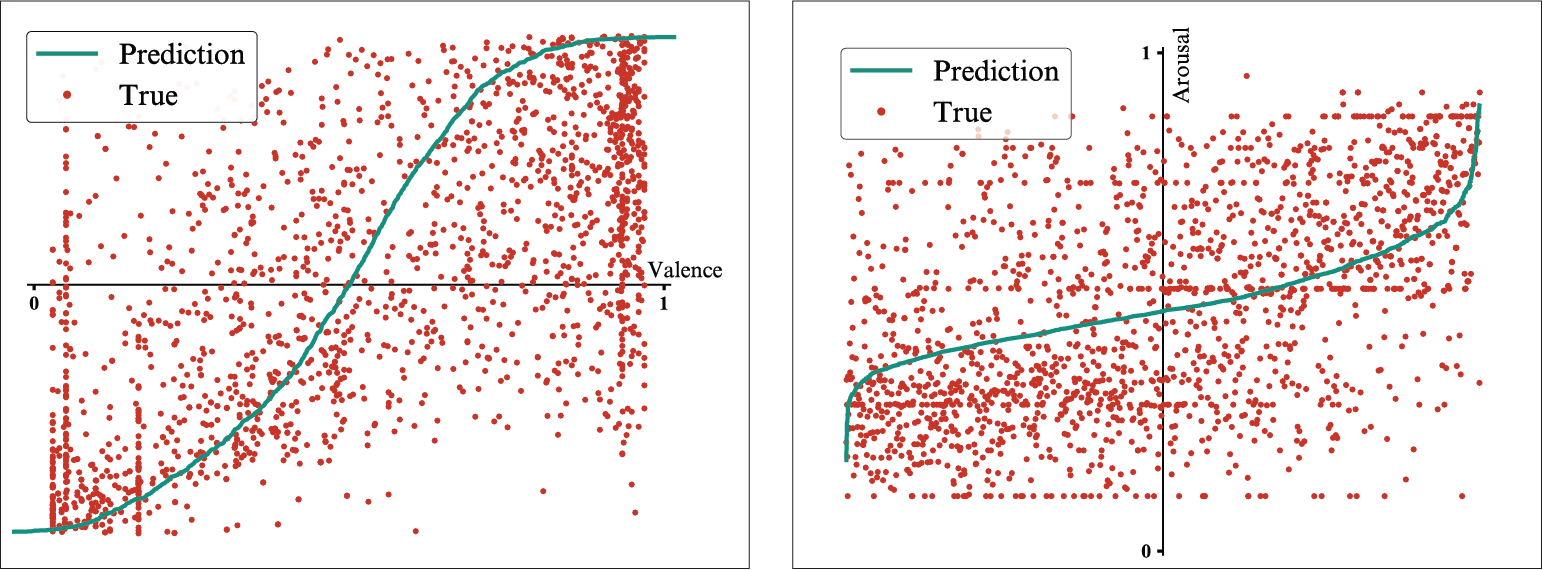
Model trained on lyrics features - Results for the valence dimension (left) and the arousal dimension (right).
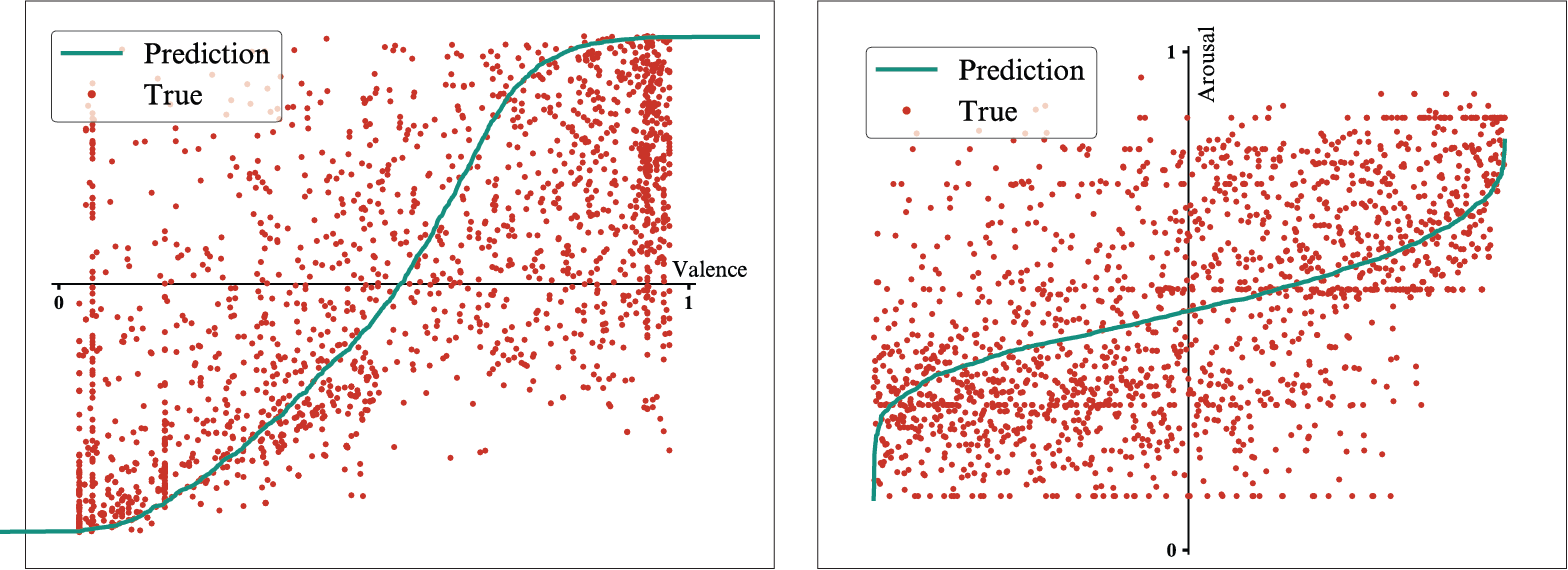
Model trained on comments features - Results for the valence dimension (left) and the arousal dimension (right).
Adding the ranges defined by the observed values and the ones defined by the predicted values, it can be noted that in general, the former exceed the latter, especially in the case of the valence predictions made by the comments model. This results, to some extent, in better defined distribution in the four quadrants.
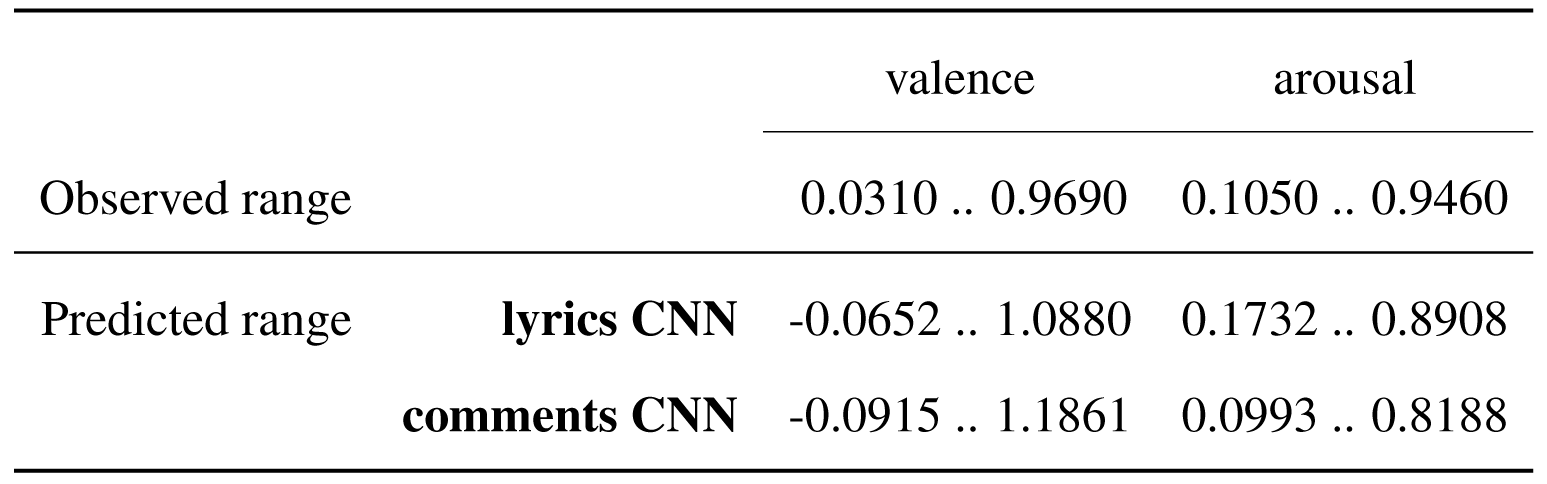
Ranges of observed and predicted values for the model trained on the lyrics features and on the comments features.
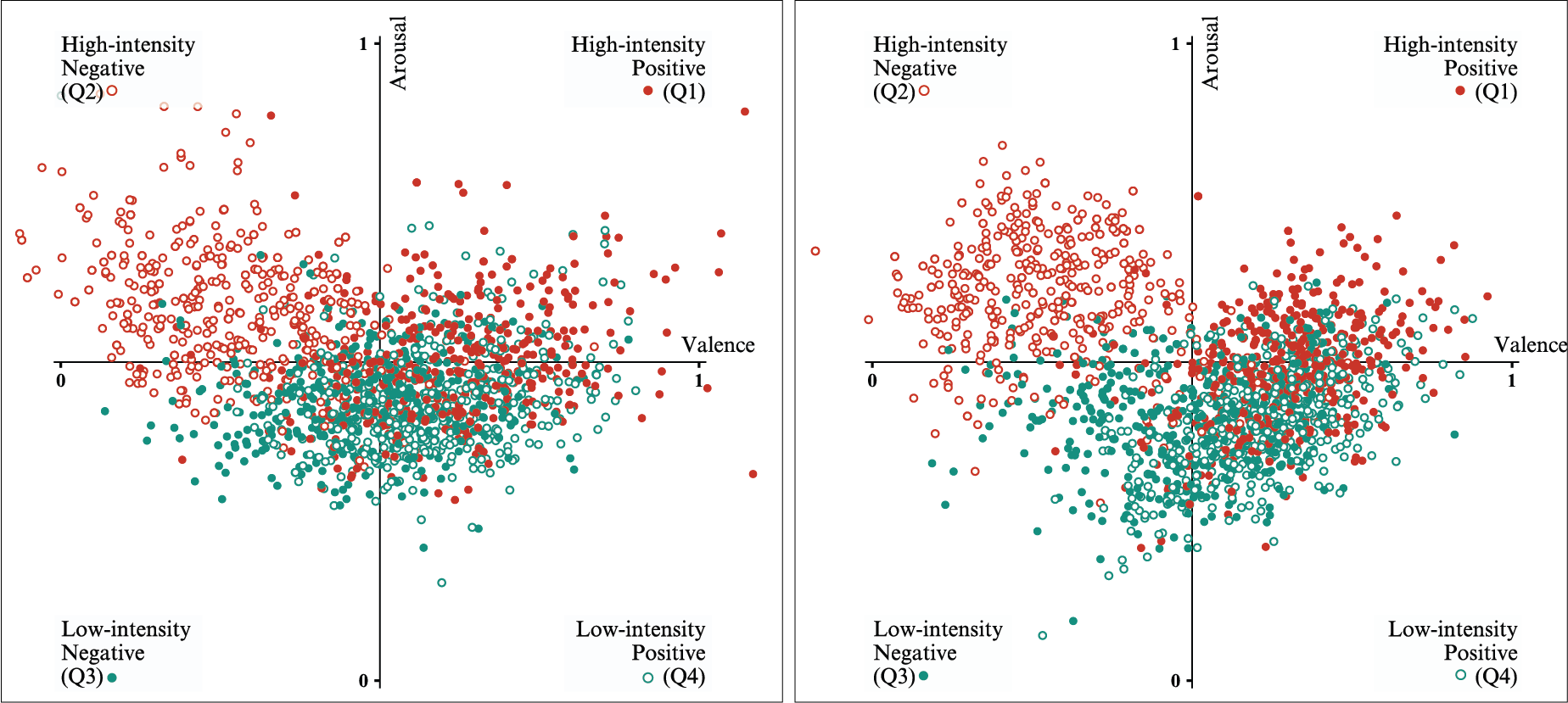
Model trained on lyrics features (left) and on comments features (right) - Results for valence and arousal in the space of emotions described by the four quadrants.
The good accuracy of predictions in the second quadrant can be attributed to the process of augmentation, where 20% of the words in duplicate lyrics and comments have been replaced with synonyms. This observation can be addressed by choosing a larger proportion of words to be replaced or by employing another text augmentation technique, such as reordering sentences.
For a better appreciation of the role each of the three modalities described above has in experiencing music from the listener position, the configurations used for learning from the three types of data are presented collectively and analysed comparatively.
When referring to the model trained on the audio features, audio model and audio CNN are used interchangeably and in the case of the other two modalities, the same conventions previously defined will be used, specifically lyrics model or lyrics CNN for the model trained on lyrics features and comments model or comments CNN for the model trained on comments features.
The first analysis perspective is regarding the accuracy of predictions in the four quadrants defining the 2D space of emotions. It can be noted that learning from the MFCCs features, in the case of the audio model, led to rather balanced accuracy of predictions across quadrants, as compared to learning on text features. The discrepancies in the accuracy of predictions in quadrant 2, where the data was oversampled the most and the rest of the quadrants become more visible in the cases of the lyrics and comments models. This indicates, as stated before, that the augmentation strategy need to be improved.
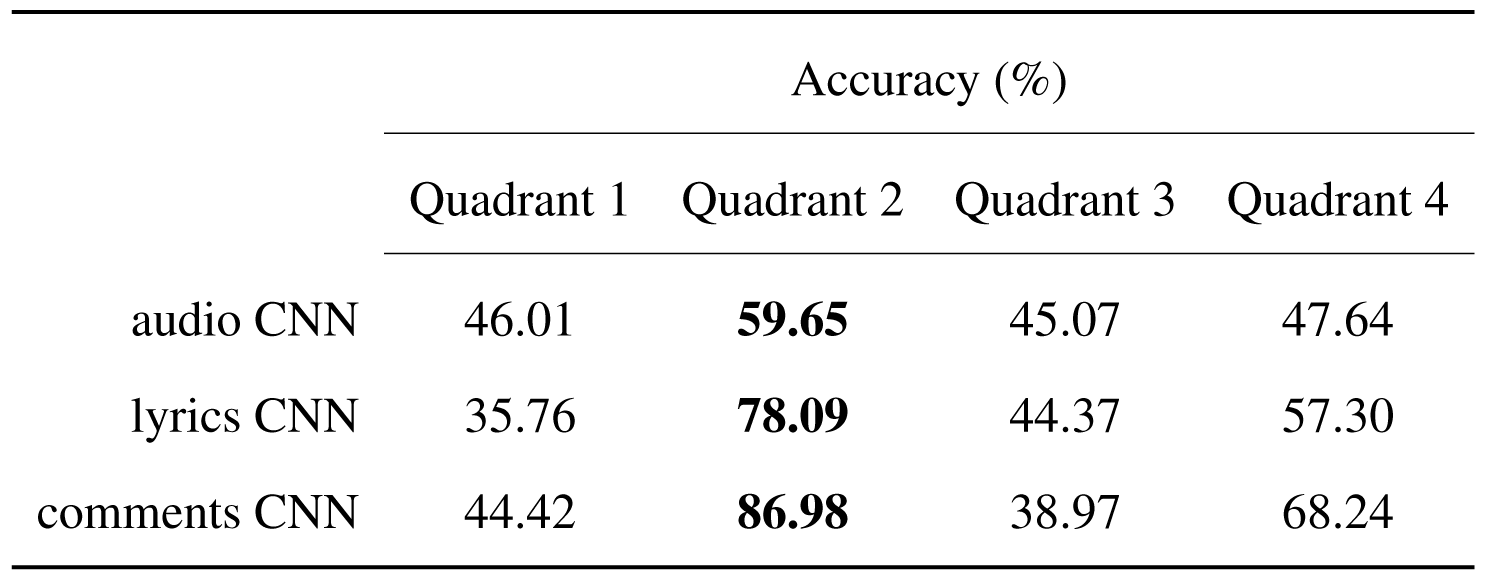
Comparison of the accuracy of the quadrant predictions between the three configurations based on the audio, lyrics and comments features.
Computing the errors of predictions MAE and MSE and the coefficient of correlation R2, the most important observations is regarding the relation between the input features and the two dimensions of the emotion space.
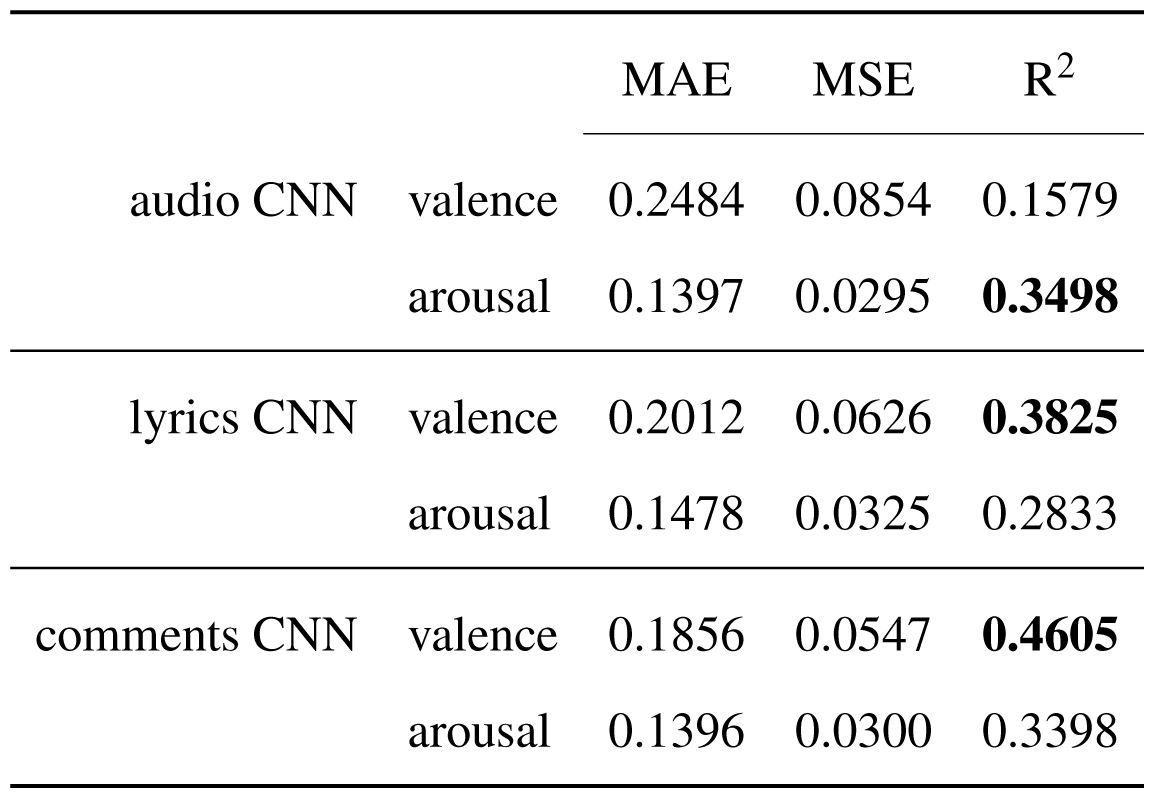
Comparison of the performance metrics between the three configurations based on the audio, lyrics and comments features.
While the audio features have a greater influence on the arousal predictions, the text features -lyrics and comments- have a stronger effect on the valence predictions. This can be considered a translation of the way humans extract emotions differently from different types of information: it is easier to describe the intensity of an emotion from the melody/beat and the positive or negative energy of an emotion is detected better from lyrics or, even more directly, from the comments explaining the meaning of the lyrics.
This constitutes motivation for the multimodal strategies described further on.
The scope of the following experiments is to get closer to the complexity of a musical experience, by incorporating different type of features into the training of one model. This is achieved by combining two-by-two the previously trained models and keeping parts of the knowledge gathered during the unimodal training process.
Considering this multimodal approach, two experiments are described, as follows: the first experiment consists in the fusion of the models trained on audio features and on lyrics features, respectively and the second experiment consists in a configuration incorporating the model trained on audio features and the model trained on comments features.
These are performed by keeping the convolution layers along with the already learned parameters and concatenating the outputs to be further fed to a sequence of two linear layers mapping to the output. Therefore, the architecture of the resulted model consist in a pre-trained segment composed of the convolution blocks of the model trained on audio features and the convolution block of the models trained on lyrics features and on comments features, respectively. The feature maps resulted from these configurations are concatenated and fed to the untrained part of the fusion model represented by a linear layer with 256 hidden units, followed by the output layer. Each of the linear layers is preceded by a Dropout layer with a probability of 50%.
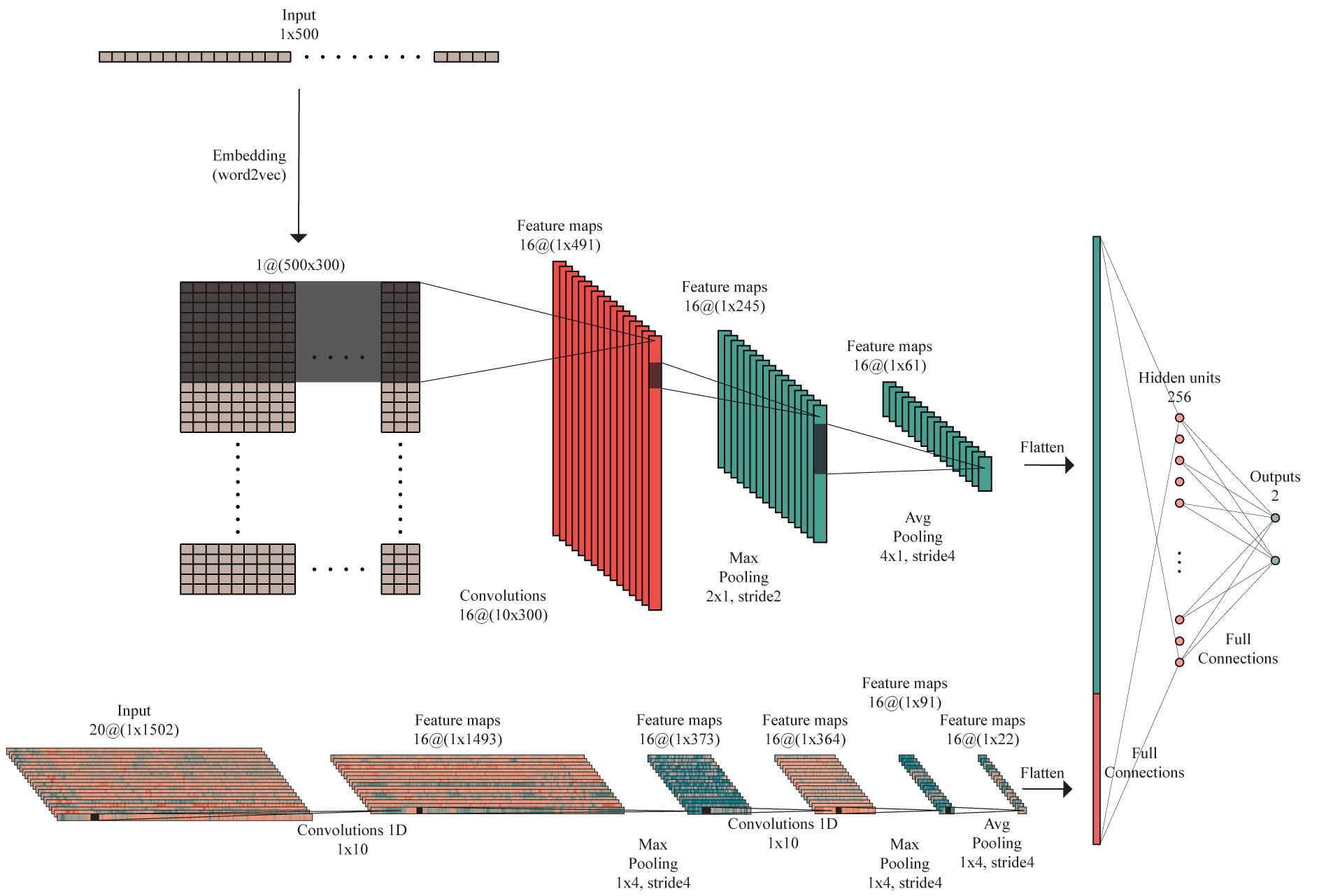
Architecture of the 2D-output fusion model trained on audio and lyrics/comments features
It can be noted that the flattened feature maps resulted from the two branches of the neural network have different sizes, the training of this fusion model being performed on data where ~75% comes from lyrics or comments features and ~25% comes from audio features. This might constitute a direction to be explored in the future, along with the amount of pre-trained parameters used.
For the results to be analysed easily, some name conventions are defined and used: audio-lyrics model and audio-lyrics CNN for the fusion of the audio and lyrics fusion model and audio-comments model and audio-comments CNN for the audio and comments fusion model.
By computing the firs set of regression metrics, the predictions made by both models in the arousal dimension are more accurate then the predictions in the valence dimension, with only slight improvements visible in the case of audio-comments approach.
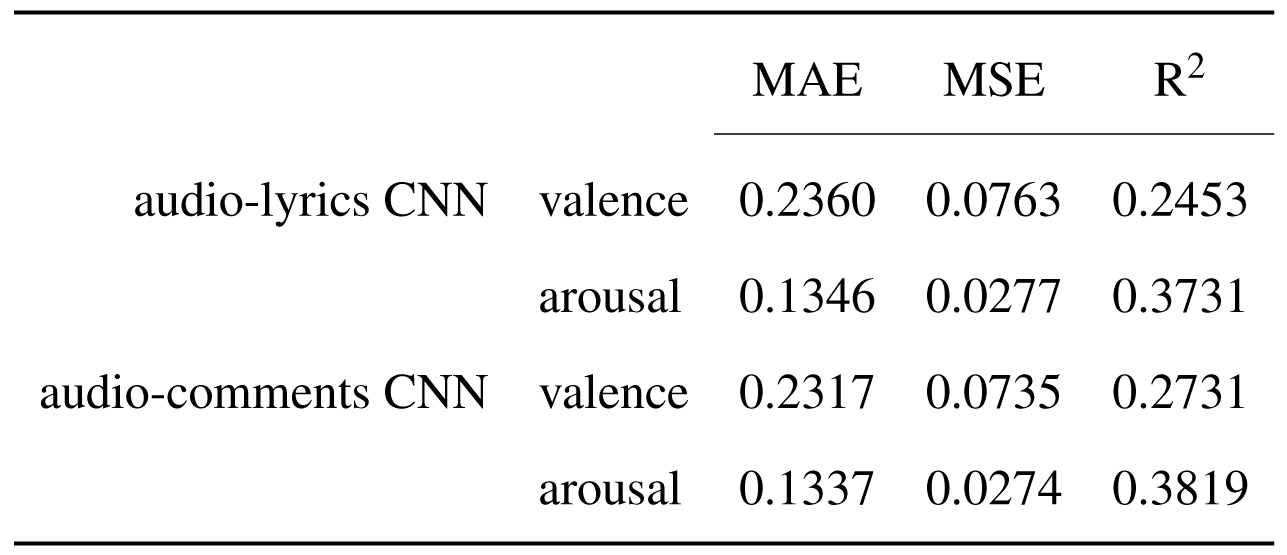
Performance metrics for the fusion model trained on audio and lyrics features and for the fusion model trained on audio and comments features.
The visualizations of the predicted values compared to the observed values for the audio-lyrics fusion and for the audio-comments fusion display, in both cases, better fitted observed values in the arousal dimension when compared to the predictions in the valence dimension.
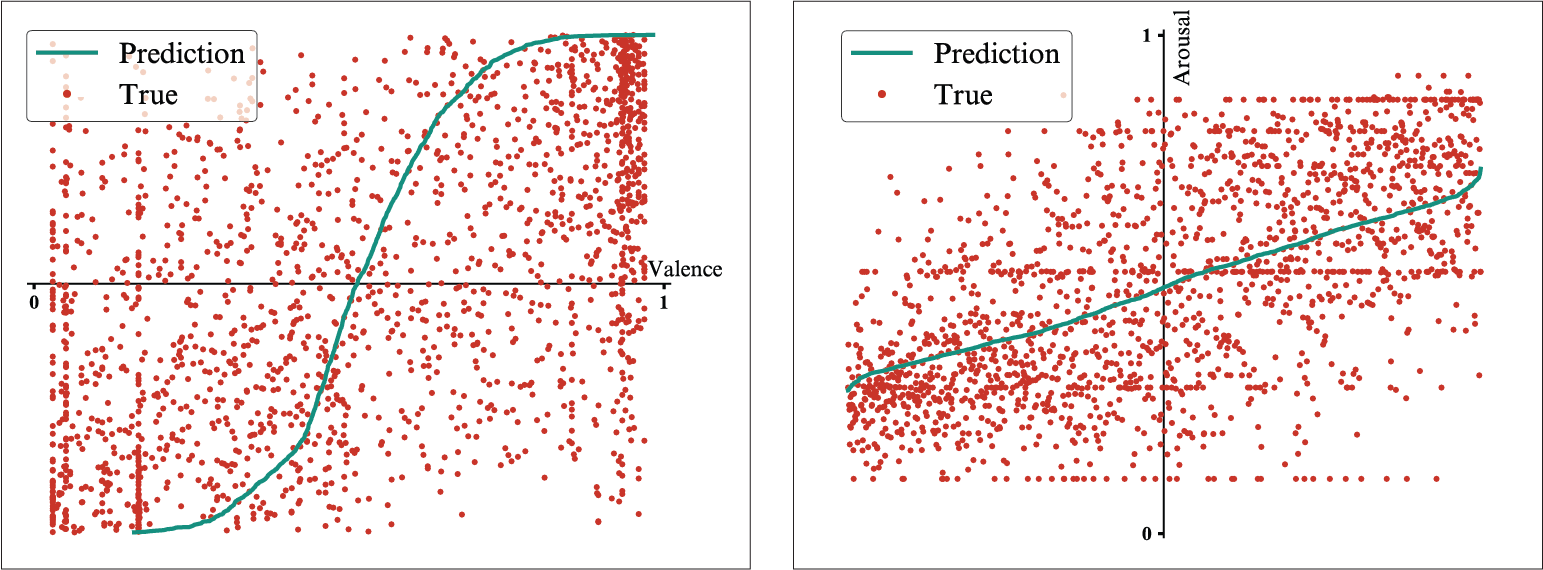
Fusion model trained on audio and lyrics features - Result for the valence dimension (left) and for the arousal dimension (right).
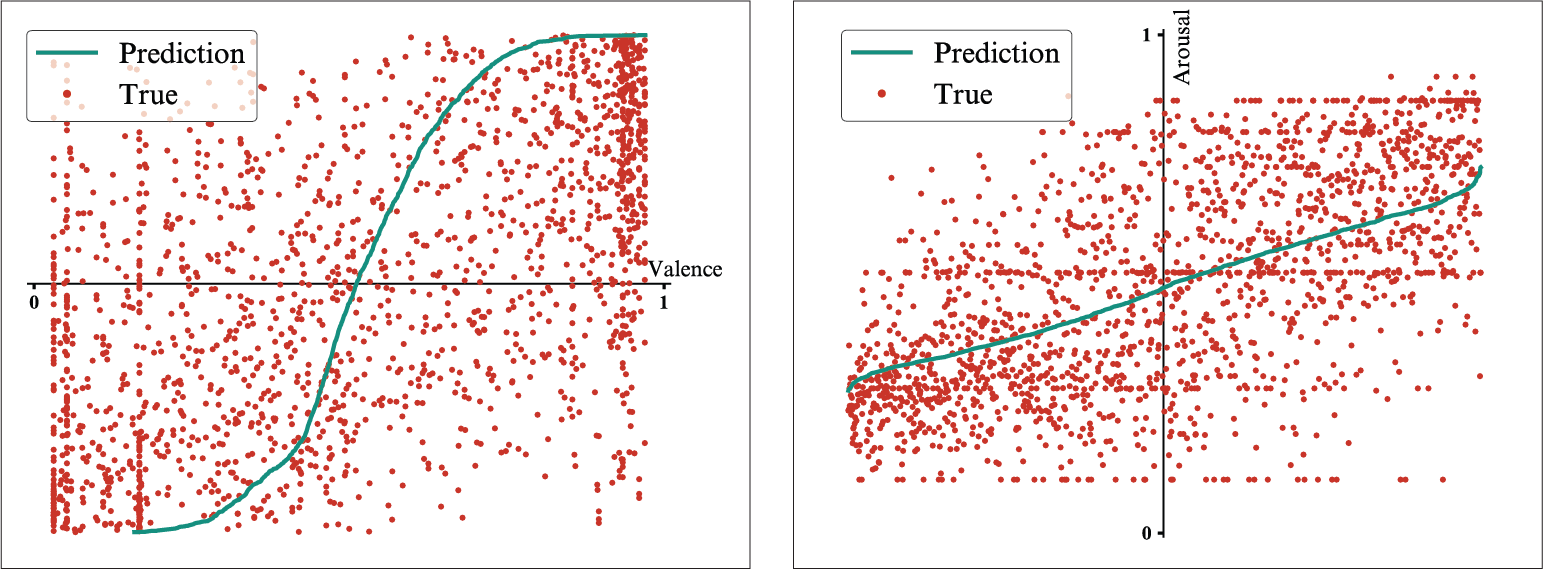
Fusion model trained on audio and comments features - Result for the valence dimension (left) and for the arousal dimension (right).
At the same time, the range defined by the predicted arousal values is much narrower than the range defined by the expected arousal values, both upper and lower partitions of the observed range being poorly predicted, while in the case of the range defined by the valence predictions, the upper limit matches almost perfectly the observed range. The poorly approximated range of values reflects in the spread of the predictions in the emotions space, that cover a limited area.
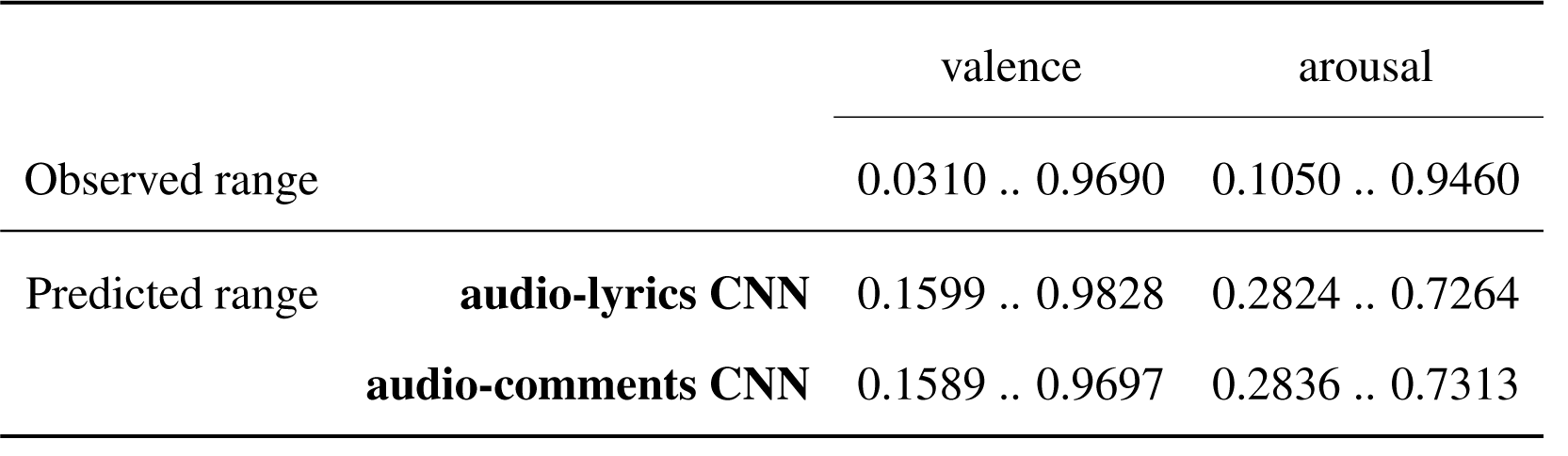
Ranges of observed and predicted values for the fusion models trained on the audio and lyrics features and on the audio and comments features.
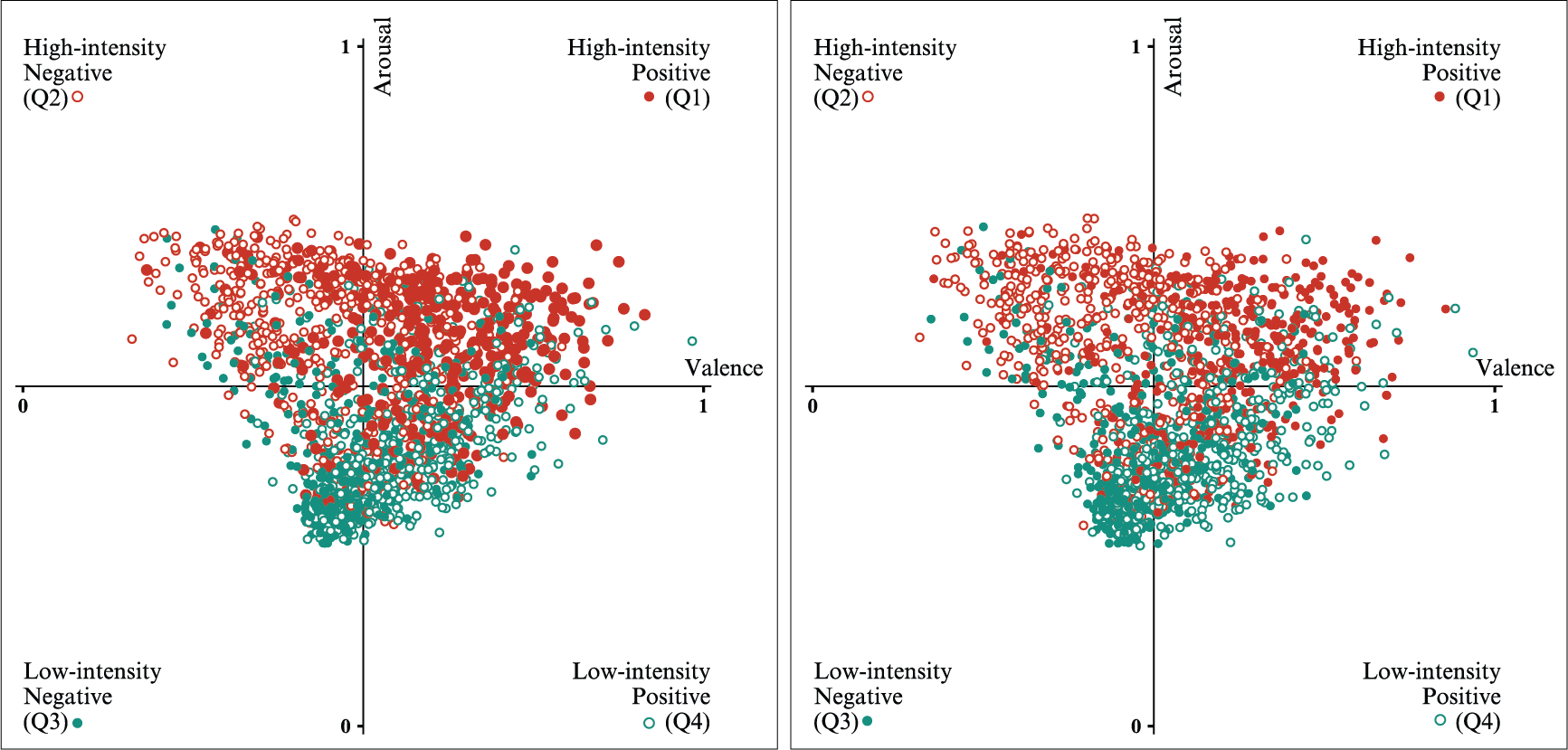
Fusion models trained on audio and lyrics features (left) and on audio and comments features (right) - Result for valence and arousal in the space of emotions described by the four quadrants.
Despite this aspect, it can be noted that, regarding the boundaries of the four quadrants, the predictions made by the audio-comments model are slightly distancing from the center and moving towards the corners of the emotion plane, the data belonging to the same quadrant being more gathered.
To summarize the effect including multiple musical dimensions has on the learning process of recognizing emotions, a comparative analysis of three models previously discussed is presented.
In order to facilitate the comparison the following name conventions are defined: the model trained on solely audio features is referred to as audio model or audio CNN, the fusion model trained on both audio and lyrics features is announced by audio-lyrics model or audio-lyrics CNN and audio-comments model and audio-comments CNN are used for the fusion model trained on both audio and comments features.
The first aspect analysed is with regard to the accuracy of predictions in the four quadrants defining the emotion space. In the case of the audio model, the most oversampled quadrant through augmentation (quadrant 2) held the best accuracy in predictions. In the case of the fusion models, it can be observed the higher accuracy of predictions in quadrants 1 and 2, that represent emotions with high intensity, as compared to quadrants 3 and 4, representing emotions with low intensity. Therefore, it can be concluded that the arousal predictions made by the fusion models are slightly exaggerated towards larger values.
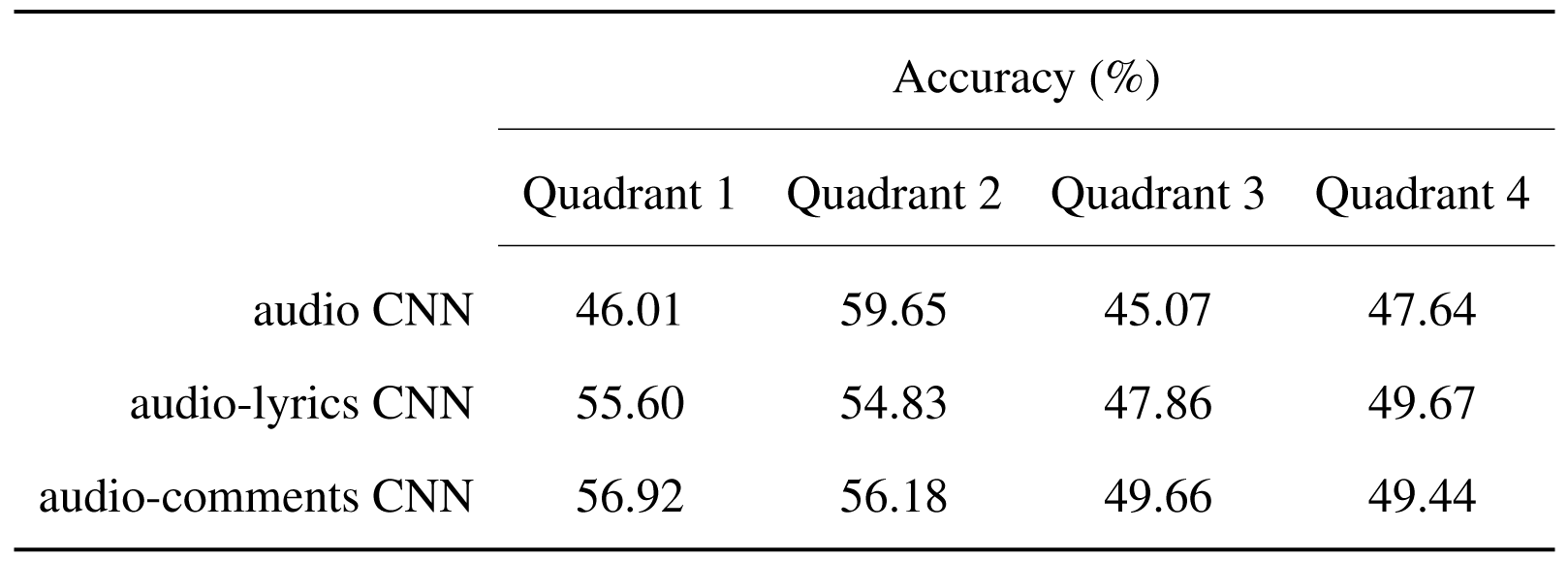
Comparison of the accuracy of the quadrant predictions between the model trained on solely audio features and the two fusion models trained on audio and lyrics features and on audio and comments features, respectively.
Computing the regression metrics for each model, the most important observation is regarding the changes in the relations between the input features and the two dimensions of emotion.
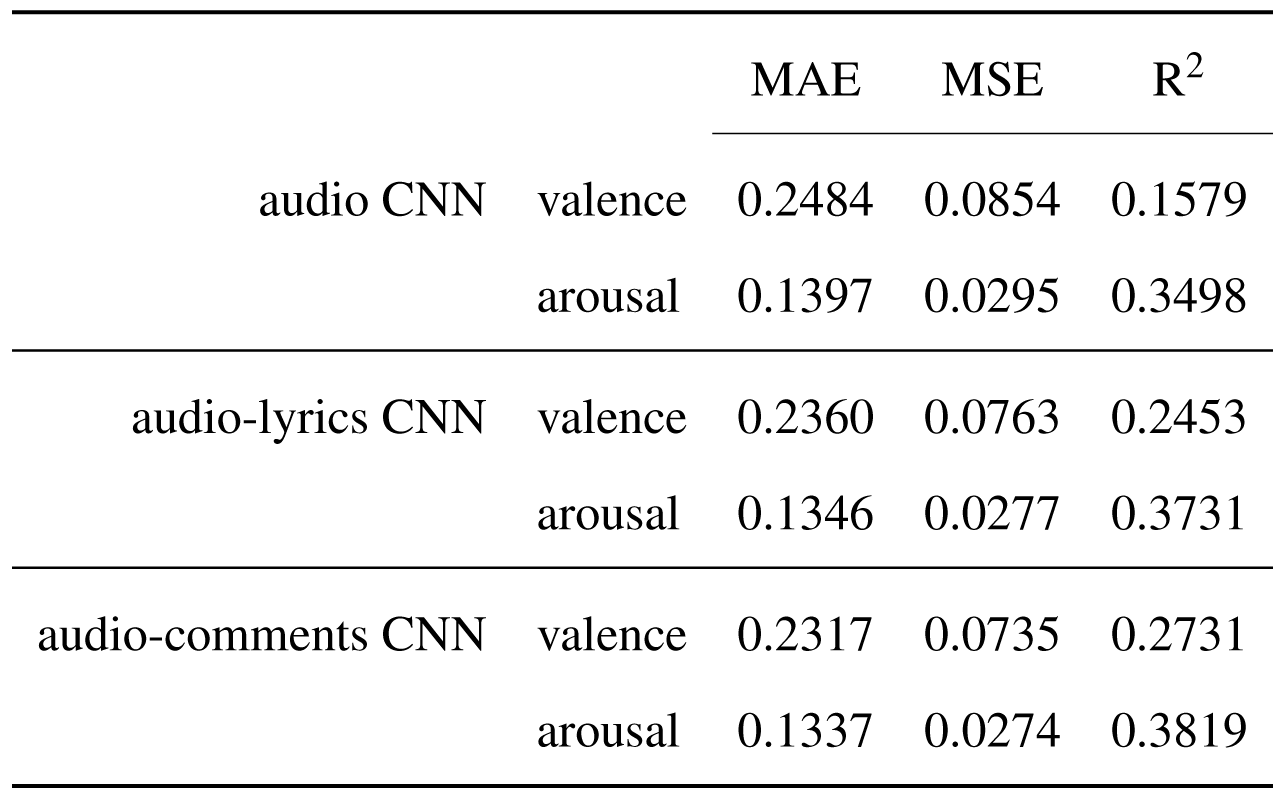
Comparison of the performance metrics between the model trained on solely audio features and the two fusion models trained on audio and lyrics features and on audio and comments features, respectively.
While the R2 scores for the audio model highlight the difference between the strong influence the audio features have on the arousal dimension and the weak influence on the valence dimension, when introducing text features that have greater effect on the valence than on the arousal dimension through the fusion models, this difference is getting smaller and the R2 score computed for the valence predictions is getting closer to the R2 score for the arousal predictions.
Analysing the MAE and MSE errors values, it can be noted that the fusion models improved only slightly the errors of predictions made by the audio model, the distance between the errors on the arousal dimension and the errors on the valence dimension remaining significant.
It would appear that the characteristics of training a neural network on solely audio features stand out when approaching a fusion of this model and a model trained on lyrics or comments features, despite the fact that the data used to train the fusion model consists in patterns of text features in a greater proportion than the patterns of audio features. It is worth investigating in the future the role different abstraction levels of the input features have on the learning process, as the patterns from the text features used to train the fusion model resulted after a single convolution operation, while the patterns from audio features used in training the fusion configuration resulted after two convolution operations.
The presented work investigated possible approaches to Music Emotion Recognition, by employing various set of tools.
Starting with a collection of introductory experiments (unimodal MER), the observations and the insights gained served as foundation for a more comprehensive and diverse analysis of the task. This involved the construction of a new dataset to meet the desired characteristics. Therefore, by making use of the social tags in the annotation process, a collection of $9\,972$ songs with their corresponding lyrics and comments was created.
More complex experiments were conducted on this dataset, tackling the use of other modalities besides the audio features, specifically lyrical text data and comments text data. These were first analysed separated, followed by fusions between them.
Maybe the most important observation in this context is represented by the quality of annotations. At the end of this work, the reliability of annotations extracted from social tags is questioned. As shown in the figures below, the most frequent emotion tag calmness appears to have a neutralizing effect and results in a very regular display of data in the emotion space, with combinations of calmness & sadness emotion words in tracks' tags defining the bottom edge and combinations of calmness & happiness defining the right edge.
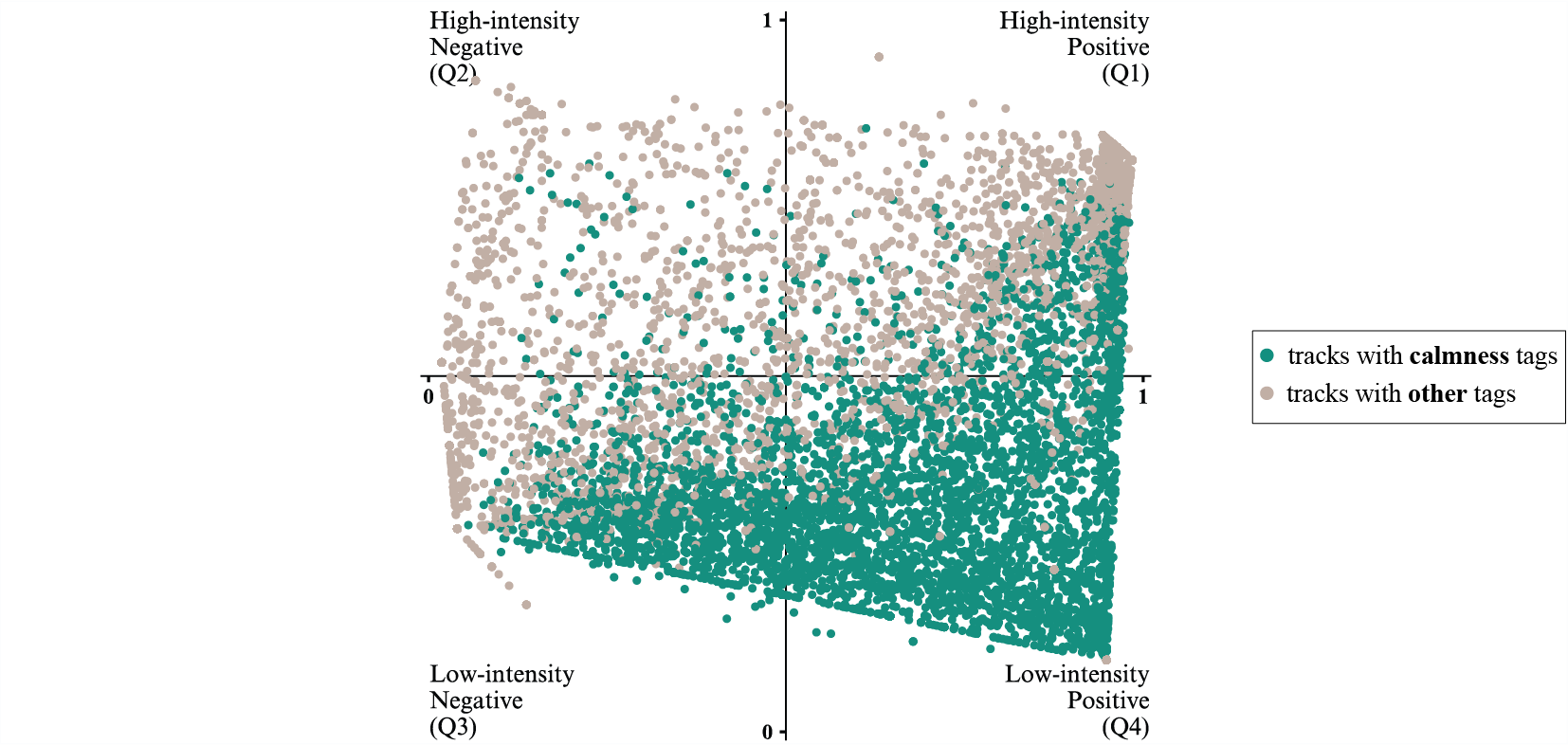
Distribution of data from the new dataset in the emotion space - Occurrence of calmness emotion word in tracks' tags.
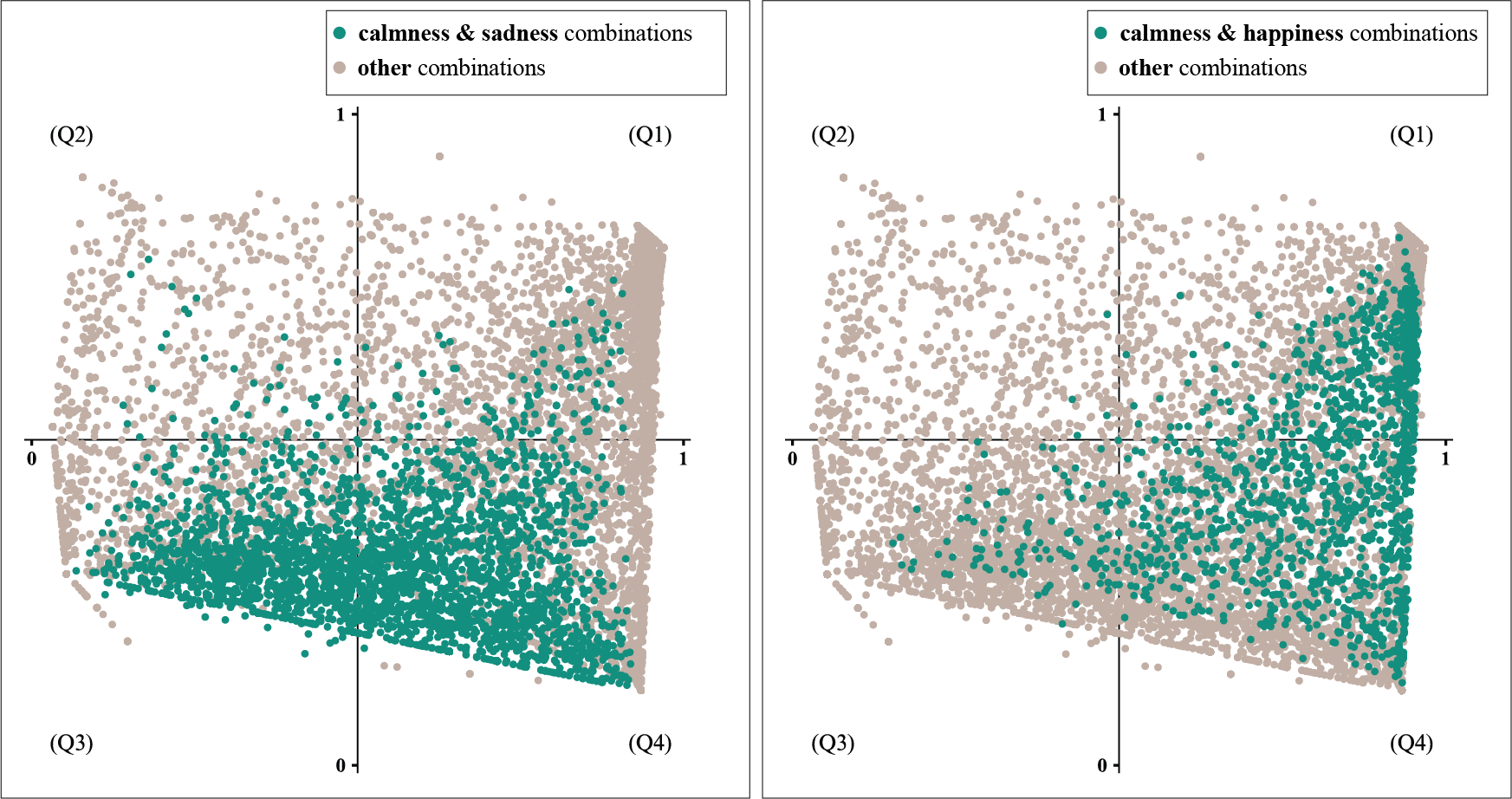
Distribution of data from the new dataset in the emotion space - Tracks with calmness & sadness tags (left) and tracks with calmness & happiness tags (right)
This problem might be addressed by implementing a penalization system considering the occurrences of emotion tags in the dataset. One other possibility is using the comments modality to extract valence and arousal values.
Improvements could be made in regard to the features selected from the lyrics and comments modalities. It is worth investigating the behaviour of the regression when including Part of Speech processing or an analysis of structure in the case of lyrics data.
The computational resources still representing a clear limitation in terms of experimenting recognizing emotions from various audio features, improvements in the case of audio modality could be made by selecting multiple excerpts from the initial signal, this way capturing a greater variety of patterns.
To conclude, this study represents a well documented collection of experiments in terms of evaluation of the performance, that can serve for future analysis, which open the possibility to different approaches on the task of recognizing emotions in music.